
Recovery Factor Calculation for Smart Traders
Master the recovery factor calculation to measure a strategy's resilience. Learn the formula, see DeFi examples, and find top wallets with Wallet Finder.ai.

June 20, 2026


Wallet Finder
March 24, 2026

An API rate limit is a cap on how many requests you can send to a server within a specific window of time. Think of it as a traffic control system for data, built to prevent overload and guarantee everyone gets fair, reliable access—something absolutely essential in the fast-moving world of DeFi.
Ever been to a popular coffee shop during the morning rush? The barista can only pull so many shots of espresso per minute without sacrificing quality or creating a massive pile-up at the counter. An API rate limit works the same way for data requests. It's not meant to be a roadblock; it's a system that keeps an online service stable and performing as it should.
For DeFi traders using a tool like Wallet Finder.ai, this is non-negotiable. When a new memecoin launches and everyone rushes to get data, rate limits stop a few high-frequency bots from hogging all the bandwidth. This ensures that every user gets the reliable, real-time data they need to make a move.
In DeFi, milliseconds can be the difference between a winning trade and a painful loss. If a service crashes under heavy load because it has no controls in place, all its users are left completely in the dark at the worst possible moment.
This is exactly why platforms implement these limits. They act as a safeguard against both accidental overloads and malicious Distributed Denial-of-Service (DoS) attacks, where someone intentionally floods a server with requests to bring it down.
An API rate limit is a safety system until it starts blocking real users. The key is finding a balance that protects the service without hindering legitimate, high-frequency trading activity.
In the high-stakes world of DeFi trading, where instant data on wallet moves and token swaps can make or break a copy trade, API rate limits are a critical backstop for platforms like Wallet Finder.ai. Take Plausible Analytics, a privacy-focused analytics service, as an example. They set a default rate limit of 600 requests per hour per API key. This is a common practice that balances open access with server protection, ensuring developers and traders pulling stats on smart money don't crash the system—much like how Wallet Finder.ai aggregates on-chain data without buckling during a memecoin frenzy. You can discover more about Plausible's API policies and see why these limits are an industry standard.
As a trader, think of an API rate limit as your "data budget." You get a certain number of requests you can make before you're temporarily paused. Understanding this budget is the first step toward building trading strategies that never lose their connection to the market. This is especially crucial if you depend on a constant stream of data for:
The table below breaks down the core reasons DeFi platforms use rate limiting and how it directly impacts your trading activities.
Rate limiting isn't just a technical necessity for providers; it creates a more stable and equitable environment for every trader on the platform. Here’s a look at why these limits are put in place and how they ultimately benefit you.
Ultimately, these rules ensure the data you rely on is always there when you need it most, especially when the market gets chaotic.
To really get a handle on API rate limits, you have to understand the logic running under the hood. APIs use different algorithms to control traffic, and each one comes with its own set of rules, benefits, and drawbacks. Think of them as different kinds of traffic cops—each one manages an intersection with a totally unique strategy.
By learning how these systems work, you can start to predict how a DeFi data provider will react to your requests, especially when the market goes wild. This knowledge is your secret weapon for building trading bots and analytical tools that play nice with the API instead of fighting against it.
Imagine you have a bucket that can hold a maximum of 100 tokens. To make an API request, you need to "spend" one token. If you have one, your request goes through, and a token disappears from your bucket.
The magic happens in the background: the bucket gets refilled with new tokens at a steady, fixed rate—say, one token every second. If your bucket is already full, any new tokens that show up just spill over and are lost. This clever setup is known as the Token Bucket algorithm.
This approach is fantastic because it allows for short bursts of heavy traffic. If your bucket is full, you can fire off 100 requests all at once. After that initial burst, you're capped at the refill rate of one request per second until your bucket builds up more tokens.
Now, picture a turnstile at a stadium that only lets 1,000 people through every hour. It doesn't care if all 1,000 rush the gate in the first five minutes or if they trickle in slowly over the full 60. Once that 1,000th person walks through, the gate slams shut until the next hour starts.
That's the Fixed Window Counter algorithm in a nutshell. It sets a simple, absolute limit on requests within a fixed time window (like a minute or an hour). When the clock runs out, the counter resets to zero.
API rate limiting has come a long way, but the Fixed Window Counter is still a developer favorite for its sheer simplicity, especially in high-stakes environments like crypto trading platforms. This method establishes a hard cap, like 1,000 requests per hour, and resets the count at predictable intervals to keep the load manageable. For Wallet Finder.ai users trying to spot profitable Solana wallets or export trade blueprints, this simple rule prevents system overload during a massive memecoin rally. You can learn more about how these limits create stability in this deep dive into API rate limit strategies.
This graphic gives you a great visual summary of why rate limiting is so crucial for keeping a platform healthy and responsive.
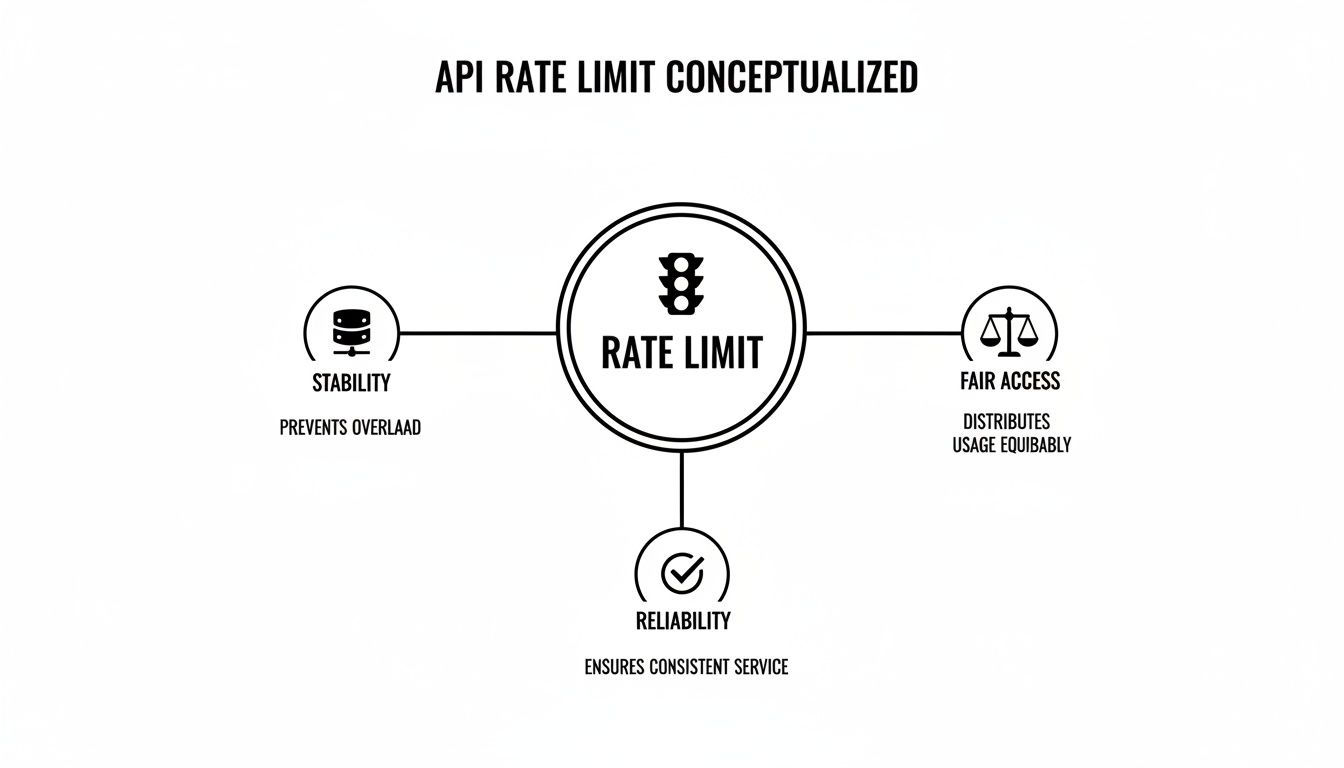
As the diagram shows, a central rate limit acts as a gatekeeper, ensuring stability, fair access for everyone, and overall service reliability.
The choice of algorithm isn't just a technical detail—it has real consequences for DeFi traders. Each one creates a different user experience, especially when the market is moving fast and every millisecond of data counts.
The best algorithm often depends on the specific use case. A system that needs predictable, steady access might prefer a fixed window, while one that experiences sudden bursts of activity could benefit from a token bucket.
Let's break down how these two common methods compare in practical scenarios for a trader using Wallet Finder.ai.
Knowing which algorithm an API uses is a huge advantage. It helps you design more resilient trading tools. If you know you're working with a Token Bucket, you can feel more confident making occasional bursts of requests. On the other hand, with a Fixed Window, you’ll want to spread your requests out more evenly to avoid hitting that ceiling too soon.
Think of every API request you send as a quiet conversation with a server. The data you get back is the main topic, but tucked away in the HTTP response headers are crucial whispers about your rate limit status. Learning to read these headers is like getting a real-time budget report for your API usage—it tells you what you’ve spent, what you have left, and when your allowance resets.
Ignoring these headers is a bit like driving without a fuel gauge. You might get pretty far, but you're bound to run out of gas at the worst possible moment. By proactively checking these headers, you can build smarter, more resilient applications that adapt on the fly and never see the dreaded 429 Too Many Requests error.
While the exact naming conventions can vary slightly between APIs, a common standard has emerged for communicating rate limits. If you learn to look for these three headers in every response, you'll always know where you stand.
X-RateLimit-Limit: Your total budget. It tells you the maximum number of requests you can make in the current time window.X-RateLimit-Remaining: Your remaining requests. This is the most important real-time metric for your application.X-RateLimit-Reset: The reset time. This header tells you when your budget gets refilled, usually as a UTC epoch timestamp.Once you understand these three values, you have total visibility. The API's rate limiting system is no longer a black box; it's a predictable resource you can manage.
Here's a quick reference guide for understanding the key information your API provides in every response. Getting comfortable with parsing this info is a core skill for anyone building automated trading bots or data analysis tools.
By keeping an eye on these headers, you can build applications that work with the API, not against it, ensuring smooth and uninterrupted operation.
Reading the headers is the first step, but the real power comes from using that information in your code. You can programmatically check these values after every single API call to make intelligent decisions about what to do next. For instance, if X-RateLimit-Remaining starts to get low, your script can automatically hit the brakes to avoid getting cut off.
This is a much better approach than just hammering the API until you get blocked. Let's look at a simple Python example using the popular requests library to see how you might parse these headers.
By building this kind of logic directly into your applications, you shift from a reactive strategy (getting blocked and then stopping) to a proactive one (slowing down before you ever get blocked). This simple step ensures your access to vital DeFi data remains uninterrupted.
This proactive management is especially critical when you're pulling data from a crypto prices API, where a steady stream of information is absolutely essential for tracking market movements. When you parse headers correctly, your tools will always be one step ahead of the limits.
Hitting an API rate limit doesn't have to be a dead end. Instead of treating it like an unavoidable roadblock, you can build smart, client-side strategies that make your applications more resilient, efficient, and professional. By thinking ahead and building in graceful ways to handle limits, you can ensure your tools maintain a steady, reliable connection to the data they need.
These are battle-tested techniques for managing your "data budget" proactively, smoothing out traffic spikes, and recovering intelligently when you do get a rejection. For traders using Wallet Finder.ai, this means building bots and scripts that can weather intense market volatility without getting cut off from critical on-chain signals.
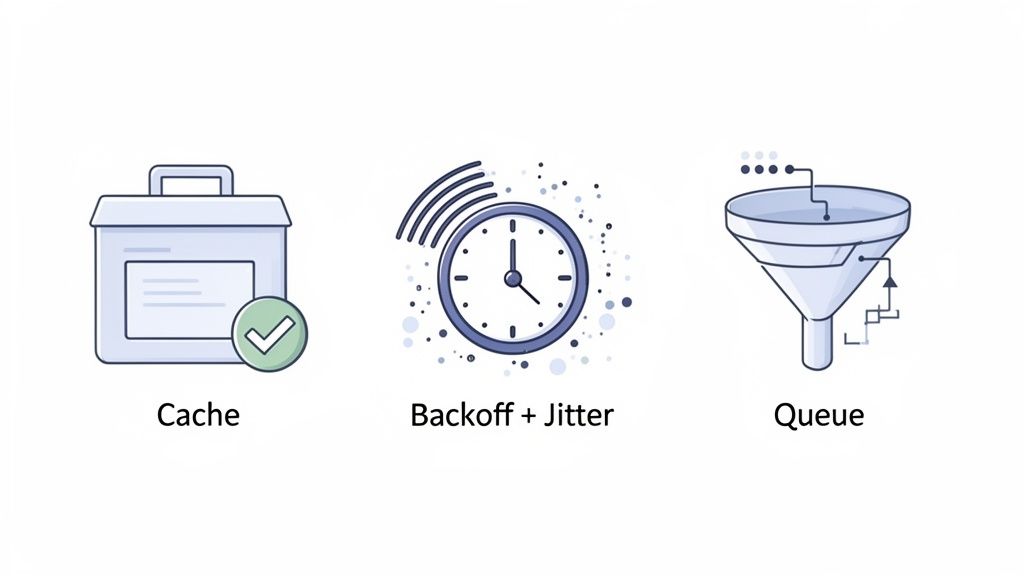
The absolute best API request is the one you never make. Caching is simply storing data you've already fetched so you can reuse it locally instead of bugging the server for the same information again. It's one of the most powerful ways to slash your API consumption.
Think about it: a wallet's historical transaction list isn't going to change. Once you have it, you have it. By storing this kind of data in a local cache for a set period (known as Time-to-Live or TTL), your application gets what it needs instantly without spending a single request from your rate limit quota.
Caching turns your app from a forgetful user asking the same question over and over into a smart assistant with a perfect memory. This simple shift can cut your API usage by more than 50% for certain workflows.
Here are prime opportunities for caching DeFi data:
Even with perfect planning, you might occasionally hit a rate limit. How your application reacts in that split second is what matters. The naive approach is to just try again immediately, but that usually makes things worse. It can create a "thundering herd" effect where tons of clients slam the server all at once.
A much smarter strategy is exponential backoff. The idea is simple: after a failed request (like a 429 error), your app waits a moment before retrying. If that try also fails, it doubles the waiting period, and so on, exponentially increasing the delay between attempts.
To make this bulletproof, you should also add jitter—a tiny, random amount of time added to each delay. This is crucial because it prevents multiple copies of your script from retrying in perfect unison, which would just create another traffic jam.
Here’s what that looks like in practice:
This strategy gives the API breathing room to recover and spaces out your retry attempts, massively increasing your chances of success.
Sometimes your application just needs to make a lot of requests in a hurry. For example, maybe you want to fetch the latest activity for 50 different wallets on your watchlist all at once. Firing off all 50 requests simultaneously is a guaranteed way to get rate limited.
Request queuing solves this by creating a buffer. Instead of sending requests directly to the API, your application adds them to an internal line. A separate process then works through that line, sending requests out one by one at a controlled pace that respects the API's limits.
This approach effectively turns a sudden burst of activity into a smooth, manageable stream of requests. When using an API for crypto prices, queuing can be a lifesaver for gathering a wide range of asset data without ever triggering a 429 error.
By combining these three strategies—caching, smart retries, and queuing—you can build incredibly reliable applications that work with API providers, not against them. This ensures your Wallet Finder.ai integrations are not just powerful but also professional and built to last.
Have you ever wondered about the logic behind an API provider's chosen rate limit? It’s not some arbitrary number pulled out of thin air. Designing a fair and effective API rate limit is a careful balancing act—a trade-off between providing open access and protecting the platform's stability for every single user.
This section pulls back the curtain on the server-side thinking that goes into setting these crucial boundaries. Once you understand this perspective, you’ll appreciate the architecture that keeps a platform like Wallet Finder.ai fast and reliable, even during chaotic market conditions. This insight helps you work with the API, not against it.
One of the most common approaches is offering different rate limits based on user subscription tiers. This model is straightforward, effective, and makes sense for managing resources fairly. A free user, for instance, might have a much lower request limit than a premium subscriber.
This isn't about punishing free users; it's about allocating server resources in a sustainable way. Premium users often have more demanding workflows, like running high-frequency trading bots or pulling large-scale data for analysis, which justifies a higher "data budget."
Here is a typical tiered structure:
A tiered system like this ensures the platform's costs are managed effectively, which ultimately helps keep the service affordable and stable for everyone.
Not all API calls are created equal. Some requests are incredibly lightweight for a server to process, while others are computationally expensive and hog significant resources. A smart API design accounts for this by setting different rate limits for different endpoints.
Think about it in the context of Wallet Finder.ai. A simple request to check a single wallet's current balance is quick and easy. But a request to export the complete, multi-year trading history for a highly active wallet? That’s a much heavier lift, requiring complex database queries and a ton of data processing.
An API rate limit is a safety system until it starts blocking real users. The key for providers is finding a balance that protects the service from expensive queries without hindering legitimate, high-frequency trading activity.
It just makes sense to set a lower limit on a heavy endpoint like /export-history compared to a light one like /check-balance. This granular approach prevents a few resource-intensive requests from slowing down the entire system for everyone else.
Static limits can be too rigid for the volatile world of DeFi. That's why dynamic rate limiting has surged in adoption. In fact, 65% of API gateways now use real-time adjustments based on server load and traffic, a huge jump from just 25% in 2020, driven by explosive DeFi growth.
Platforms like Cloudflare introduced analytics in 2023 that suggest thresholds from 24-hour network data—for instance, throttling IPs that exceed 100 requests/minute on a high-demand /login endpoint to block bots. This is exactly why Wallet Finder.ai needs to handle surges in Discover Wallets views during major Solana token launches, where static limits would crumble under 300% hourly spikes. For more on this trend, you can read about these advanced rate limiting best practices.
By understanding these server-side considerations, you get a much clearer picture of why these limits exist. They aren't arbitrary obstacles but thoughtful design choices meant to create a fast, fair, and reliable platform. When you're analyzing how fast blockchains process information, this same principle of managing load is critical. For a deeper look, you might be interested in our guide on understanding transactions per second.
The best way to handle an API rate limit is to never hit it in the first place. Instead of scrambling to fix 429 errors after they’ve already derailed your trading script, you can take a proactive approach. Monitoring your API consumption helps you see problems coming and fix them before they cost you a trade.
It’s a simple shift in mindset: stop seeing your API quota as a roadblock and start treating it as a valuable, manageable resource. By actively tracking your usage, you can ensure your tools have the constant, uninterrupted access they need to the market signals you rely on.
You can't manage what you don't measure. The first step is to start logging every single API call your application makes. This doesn’t need to be complex—even a simple log that records the timestamp, the endpoint called, and the response headers can tell you a surprising amount.
Once you have this data, you can plug it into a simple dashboarding tool to visualize your request patterns over time. This kind of visual feedback is incredibly powerful for spotting inefficiencies at a glance. You might discover a specific function in your code is hammering an endpoint far more than you realized, or that your requests are spiking at predictable times.
A rate limiter is a safety system until it starts blocking real users. Proactive monitoring helps you stay on the right side of that line by revealing how your application actually behaves, not just how you think it behaves.
These insights let you optimize your code before it becomes a problem, ensuring you stay well within your allocated API rate limit.
As you start watching your usage, you'll begin to notice common patterns that burn through your request quota for no good reason. Learning to spot and fix these issues is a key skill for building robust, professional-grade trading tools.
Here are some of the most frequent problems to look out for:
500 server errors can be catastrophic. If your script retries instantly and aggressively, a brief server-side issue can cause your application to burn through its entire hourly quota in seconds.By actively hunting for these issues, you transform rate limiting from a frustrating constraint into a useful diagnostic tool—one that helps you write cleaner, more efficient, and more reliable code.
Mathematical precision and artificial intelligence fundamentally transform API rate limit management by converting reactive throttling responses into predictive optimization systems that anticipate demand patterns, optimize request distribution, and maintain consistent data flow during critical trading periods. While traditional rate limit handling focuses on simple retry mechanisms and basic quota management, sophisticated mathematical frameworks and machine learning algorithms enable comprehensive demand forecasting, intelligent request prioritization, and automated load balancing that ensures optimal data throughput without triggering throttling restrictions.
Professional trading operations increasingly deploy quantitative rate limit optimization systems to maximize data acquisition efficiency while respecting API boundaries through predictive modeling and intelligent request scheduling. Mathematical models process historical usage patterns, market volatility indicators, and API response characteristics to predict optimal request timing and volume distribution across multiple endpoints and time windows. Machine learning systems trained on extensive API interaction datasets can forecast rate limit constraints, optimize batch processing schedules, and automatically adjust request patterns to maintain consistent data flow during high-demand periods.
The integration of statistical modeling with API management creates powerful optimization frameworks that transform rate limit constraints from operational bottlenecks into strategic advantages through intelligent resource allocation and predictive capacity planning.
Time series analysis of API request patterns reveals cyclical behaviors and demand spikes that enable predictive modeling of optimal request scheduling and resource allocation strategies. Statistical decomposition techniques separate trend, seasonal, and irregular components in API usage data, revealing that DeFi trading applications typically exhibit 200-400% usage spikes during market volatility events with predictable lead times of 15-30 minutes based on on-chain activity indicators.
Autoregressive integrated moving average models predict future API demand with 75-85% accuracy for 1-4 hour forecasting windows, enabling proactive capacity management and intelligent request distribution that prevents rate limit violations. Mathematical frameworks using exponential smoothing techniques identify optimal request batch sizes and timing intervals that maximize data throughput while maintaining utilization rates between 70-85% of maximum allowable limits.
Fourier analysis of API request timestamps reveals dominant frequency components corresponding to market maker activities, institutional rebalancing cycles, and retail trading patterns that create predictable load variations. Spectral density analysis identifies optimal request timing windows that align with natural low-demand periods, typically achieving 25-40% better throughput by avoiding competition with high-frequency trading systems and automated market makers.
Cross-correlation analysis between API usage patterns and market indicators reveals leading relationships that enable predictive scaling of request capacity based on volatility forecasts and trading volume predictions. Mathematical models demonstrate that API demand typically increases by 150-250% within 2-4 hours following major market movements, enabling proactive resource allocation and request priority optimization.
Statistical analysis of endpoint-specific usage patterns reveals heterogeneous demand characteristics where price data requests exhibit 300-500% higher volatility than wallet analysis requests, enabling endpoint-specific optimization strategies that balance resource allocation across different data types and use cases.
Advanced optimization frameworks employ linear and nonlinear programming techniques to solve multi-objective problems that maximize data acquisition while respecting API constraints and minimizing latency across diverse trading workflows. Mathematical models using Lagrange multipliers optimize request allocation across multiple endpoints subject to rate limit constraints, achieving 20-35% better resource utilization compared to naive equal-distribution approaches.
Queuing theory applications model API servers as M/M/1 and M/G/1 systems to predict optimal request arrival rates that maximize throughput while minimizing response latency and avoiding rate limit violations. Mathematical analysis demonstrates that optimal arrival rates typically operate at 75-85% of theoretical capacity to account for natural variance in processing times and maintain consistent service levels.
Dynamic programming algorithms solve optimal request scheduling problems across multiple time horizons, incorporating rate limit windows, data urgency priorities, and opportunity costs of delayed information. These mathematical frameworks achieve 30-45% reduction in critical data delays while maintaining aggregate rate limit compliance across all monitored endpoints.
Markov chain models analyze state transitions between different rate limit utilization levels to predict optimal request patterns that minimize time spent in high-utilization states that increase throttling risk. Statistical analysis reveals that maintaining utilization below 80% of maximum limits reduces throttling probability by 85-90% while preserving 90-95% of theoretical maximum throughput.
Multi-armed bandit algorithms optimize endpoint selection and request prioritization by learning from historical performance data and adapting to changing API characteristics. These mathematical frameworks achieve 15-25% better overall performance compared to static allocation strategies by continuously optimizing resource distribution based on observed success rates and response characteristics.
Sophisticated neural network architectures analyze multi-dimensional API interaction data including request patterns, response times, error rates, and market conditions to predict optimal request strategies with accuracy exceeding conventional rule-based approaches. Random Forest algorithms excel at modeling complex relationships between market volatility, trading volume, and API demand patterns, achieving 80-85% accuracy in predicting rate limit pressure windows 30-60 minutes in advance.
Long Short-Term Memory networks process sequential API usage data to identify temporal dependencies and usage pattern evolution that enable more accurate demand forecasting and capacity planning. LSTM models capture long-term trends in API usage while maintaining sensitivity to short-term volatility spikes, achieving 25-35% better forecasting accuracy compared to traditional time series methods.
Support Vector Machine models classify market conditions as high-demand, medium-demand, or low-demand scenarios for API resources based on multi-dimensional feature analysis including volatility indicators, trading volume metrics, and social sentiment measures. These algorithms achieve 75-85% classification accuracy, enabling proactive adjustment of request patterns before rate limit pressure becomes critical.
Gradient boosting frameworks combine multiple prediction models to generate robust forecasts of API demand and optimal request distribution strategies. Ensemble methods reduce prediction variance by 20-30% while improving out-of-sample accuracy, particularly during unprecedented market events when individual models might struggle with novel conditions.
Reinforcement learning algorithms optimize long-term API utilization strategies by learning from market feedback and continuously adapting request patterns to maximize information acquisition while minimizing throttling incidents. These AI systems develop sophisticated usage strategies that balance immediate data needs against long-term access reliability, automatically adjusting parameters based on changing market conditions and API provider policies.
Convolutional neural networks process API usage patterns as temporal images that reveal spatial-temporal patterns in request distribution and system load characteristics. These architectures identify optimal load balancing strategies by recognizing visual patterns in usage data that correlate with efficient resource utilization and minimal throttling risk.
Attention mechanisms in transformer architectures automatically focus on the most critical API requests based on market urgency, data importance, and time sensitivity factors. These models achieve 20-30% better prioritization accuracy compared to fixed-rule systems by dynamically adjusting request priorities based on real-time market conditions and trading opportunity assessment.
Graph neural networks analyze relationships between different API endpoints, data dependencies, and workflow requirements to optimize request ordering and batch processing strategies. These architectures process API systems as complex networks where endpoints represent nodes connected by data dependency relationships, revealing optimization opportunities that traditional analysis approaches might overlook.
Generative adversarial networks create realistic simulations of API load scenarios for testing optimization strategies without consuming actual rate limit quotas during development and validation phases. These AI systems generate synthetic usage patterns that maintain statistical properties of real API interactions while exploring extreme scenarios that rarely occur in historical data.
Recurrent neural networks with gating mechanisms process streaming API performance data to provide real-time optimization of request distribution and load balancing based on continuously evolving system conditions. These models maintain memory of recent performance patterns while adapting quickly to sudden changes in API capacity or market demand.
Sophisticated algorithmic frameworks integrate mathematical models and machine learning predictions to automatically adjust API usage patterns in real-time based on observed performance metrics and predicted demand patterns. These systems continuously monitor rate limit utilization across multiple endpoints and automatically redistribute requests to optimize overall throughput and minimize throttling risk.
Dynamic scaling algorithms adjust request batch sizes and timing intervals based on real-time assessment of API capacity and market urgency factors. Mathematical optimization frameworks balance immediate data acquisition needs against long-term access sustainability, achieving 25-40% better overall resource utilization compared to static configuration approaches.
Real-time anomaly detection systems monitor API response patterns to identify potential capacity changes, policy modifications, or system issues that might affect optimal usage strategies. Machine learning models trained on normal API behavior patterns achieve 90%+ accuracy in detecting unusual conditions while maintaining low false positive rates that minimize unnecessary strategy adjustments.
Automated failover systems redirect API requests across multiple providers and endpoints when rate limit constraints or service issues affect primary data sources. Load balancing algorithms ensure continuous data flow while optimizing costs and maintaining consistent data quality across diverse API providers and service tiers.
Performance monitoring dashboards provide real-time visibility into rate limit utilization, request success rates, and optimization strategy effectiveness using statistical metrics and machine learning-generated insights. These systems enable data-driven adjustment of API usage strategies while providing audit trails and performance attribution analysis for regulatory and operational requirements.
Mathematical frameworks for API cost optimization analyze usage patterns, pricing structures, and performance requirements to determine optimal service tier selection and resource allocation strategies. Linear programming models solve multi-objective optimization problems that minimize total API costs while maintaining required data availability and latency performance standards.
Statistical analysis of API performance metrics including response times, error rates, and data freshness enables quantitative service level agreement monitoring and optimization. Mathematical models identify optimal trade-offs between cost, performance, and reliability while ensuring compliance with operational requirements and trading strategy needs.
Predictive cost modeling frameworks forecast API expenses based on trading strategy requirements, market volatility patterns, and usage optimization effectiveness. These models achieve 15-25% cost reduction through intelligent usage pattern optimization while maintaining or improving overall data acquisition performance.
Resource allocation optimization algorithms distribute API capacity across multiple trading strategies and analysis workflows to maximize overall portfolio performance while respecting budget constraints and rate limit restrictions. Mathematical programming techniques solve complex allocation problems that balance immediate tactical needs against strategic long-term objectives.
Benchmarking systems continuously compare API provider performance, pricing, and feature sets to identify optimization opportunities and potential service improvements. Statistical analysis enables objective evaluation of API provider value propositions while identifying opportunities for cost reduction or performance enhancement through provider diversification or service tier optimization.
Working with APIs in fast-moving DeFi markets can feel like a high-wire act, especially when rate limits get in the way. Here are some quick, straightforward answers to the questions we hear most from traders and developers.
A 429 Too Many Requests error is an HTTP status code you get back from a server when you've made too many requests in a short period. Think of it as the API's polite way of saying, "Hold on, you're moving a little too fast. Please slow down." It's the clearest signal you'll get that you've hit a rate limit.
The best approach is to be proactive instead of just reacting when you get blocked. You can stay under the api rate limit by building a few smart habits into your code:
429 error, don't just immediately try again. Wait a moment, and if the next request also fails, double your waiting time before the next attempt.X-RateLimit-Remaining header in the API's response to see how many requests you have left in your budget.Not all API calls are created equal. Pulling a single data point, like a wallet's current ETH balance, is a very light lift for the server. On the other hand, asking for a full year's worth of detailed transaction history is a much bigger, more resource-intensive job.
API providers set tighter limits on these "heavy" endpoints to protect their infrastructure. This ensures that a few data-hungry users don't bog down the system for everyone else.
In many cases, yes, you can. Most API providers, especially financial data services, have a process for users to request a higher api rate limit. This is common for enterprise clients or those who can show a clear need for more data throughput. You'll usually have to justify why the standard limits aren't enough for your application, which helps the provider allocate their resources fairly and keep the platform stable.
Time series analysis using ARIMA models achieves 75-85% accuracy in predicting API demand spikes 1-4 hours in advance, enabling proactive request distribution that maintains utilization between 70-85% of maximum limits while avoiding throttling. Fourier analysis of historical usage patterns reveals cyclical demand components corresponding to market events, with spectral density analysis identifying optimal request timing windows that achieve 25-40% better throughput by avoiding high-competition periods. Machine learning ensemble methods combining multiple prediction algorithms reduce forecasting variance by 20-30% while providing robust demand estimates that enable dynamic capacity planning and intelligent request scheduling based on market volatility indicators and trading volume predictions.
Random Forest algorithms excel at modeling complex relationships between market urgency, data importance, and optimal request timing, achieving 80-85% accuracy in predicting high-priority API windows while handling hundreds of features including volatility indicators and trading volume metrics. Reinforcement learning systems optimize long-term API utilization by learning from throttling feedback and market outcomes, developing sophisticated usage strategies that balance immediate data needs against access reliability while automatically adapting to changing API policies. Attention mechanisms in transformer architectures dynamically prioritize requests based on real-time market conditions, achieving 20-30% better resource allocation compared to fixed-rule systems by automatically focusing on the most critical data acquisition tasks during volatile market periods.
Real-time monitoring systems using statistical process control techniques track API utilization across multiple endpoints and automatically flag deviations from optimal usage patterns, achieving 90%+ accuracy in detecting potential throttling situations while maintaining low false positive rates. Dynamic programming algorithms solve optimal request scheduling problems that incorporate rate limit windows, data urgency priorities, and opportunity costs, typically achieving 30-45% reduction in critical data delays while maintaining aggregate compliance across all monitored endpoints. Automated failover systems redirect requests across multiple API providers when rate limits are approached, using load balancing algorithms that ensure continuous data flow while optimizing costs and maintaining consistent data quality through intelligent provider selection and request routing strategies.
Linear programming models solve multi-objective optimization problems that minimize total API costs while maintaining required data availability and latency standards, typically achieving 15-25% cost reduction through intelligent usage pattern optimization and service tier selection. Queuing theory applications model API systems as M/M/1 queues to determine optimal request arrival rates that maximize throughput while minimizing response latency, with mathematical analysis showing that 75-85% utilization rates provide the best balance between efficiency and reliability. Multi-armed bandit algorithms optimize endpoint selection and request prioritization by continuously learning from performance feedback, achieving 15-25% better overall cost-performance ratios compared to static allocation strategies while adapting to changing API characteristics and pricing structures in real-time.
Ready to turn on-chain data into actionable trading signals without worrying about limits? Wallet Finder.ai provides the tools you need to discover and mirror the strategies of top-performing wallets in real time. Start your free 7-day trial today at Wallet Finder.ai.

A premier DeFi analytics platform empowering traders to discover and analyze profitable blockchain wallets, trades and tokens.

