
Recovery Factor Calculation for Smart Traders
Master the recovery factor calculation to measure a strategy's resilience. Learn the formula, see DeFi examples, and find top wallets with Wallet Finder.ai.

June 20, 2026


Wallet Finder
May 20, 2026

You've probably done this already. You find a wallet with a ridiculous run on a new token, inspect the trade history, and think the edge is obvious. Copy the buys, copy the sells, size the positions conservatively, and let the wallet do the hard part.
That's how a lot of DeFi traders end up backtesting far too late, usually after the live results don't resemble the wallet history at all.
A real backtesting framework is what separates “this wallet made money” from “this strategy is reproducible under my conditions.” In DeFi, that distinction matters more than in most markets because your outcome depends on execution details that price-only testing ignores. Gas changes the entry. Latency changes the fill. Liquidity changes the slippage. MEV changes whether the trade was even copyable in the first place.
If you're building systems around wallet mirroring, smart money tracking, or token rotation, your framework can't be a spreadsheet with a few historical candles and optimistic assumptions. It has to behave like a trading engine and it has to be skeptical by default.
Block 18,542,901 looks perfect in hindsight. A wallet buys into a fresh pool before the chart goes vertical, trims into strength, and closes the position before liquidity disappears. The trade history looks clean. The copy trade usually does not.
What failed was not the idea. It was the assumption that the observed trade was reproducible. On-chain strategies break at the point where research meets execution. The entry price in the wallet history may have depended on lower gas, less competition in the mempool, faster routing, or a pool depth that vanished once others noticed the move. A backtest that ignores those constraints turns a hard trade into an easy one.
Wallet histories are seductive because they compress a messy process into a single line item. Buy here. Sell there. Profit. That format hides the mechanics that decide whether you could have taken the same trade under your own conditions.
In DeFi, those mechanics are often the strategy.
A profitable wallet might be trading sizes that fit inside thin liquidity better than yours. It might be using private order flow that reduces MEV exposure. It might react within seconds to a contract event that your pipeline only sees after indexing lag. If your framework replays the transaction at the printed swap price, it is grading the strategy on terms you never had access to.
This gets harsher in memecoins, micro-cap pools, and newly launched pairs. One buy shifts the curve. One failed transaction burns gas and leaves you chasing a worse entry. One sandwich attack can convert an attractive setup into a trade you would have rejected if the backtest had modeled execution realistically.
A winning wallet can reflect skill. It can also reflect conditions you cannot repeat. Early allocations, favorable block placement, one extreme outlier winner, survivorship bias in the wallet sample, or incomplete data around failed transactions can all make a strategy look cleaner than it was.
Data quality is part of the problem, not an implementation detail. Missing swaps, inconsistent timestamps across indexers, token metadata errors, and silent gaps in pool history can change the result enough to approve a strategy that should have been discarded. Good research starts with filtered, replayable on-chain datasets for scalable backtesting, not a raw export and a few optimistic joins.
A useful test is simple. Remove the assumptions that flatter the result and see what survives.
The question is not whether a wallet made money.
The question is whether your system, with your latency, capital, chain coverage, and execution path, could have captured enough of that edge after costs and frictions. That is a much stricter standard, and it should be. Many DeFi traders only start asking it after live copy trading underperforms the backtest.
A professional backtesting framework exists to reject strategies that only work on screenshots. If it handles gas, slippage, liquidity decay, ordering, failed transactions, and MEV exposure with enough realism, fewer strategies will pass. That is a feature, not a bug.
At 2:07 p.m., a target wallet buys into a thin pool on Base. Your system catches the swap a few seconds later, routes a copy order, and gets a worse fill after gas spikes. The wallet's trade still looks brilliant in hindsight. Your copy does not. A professional backtesting framework has to model that gap, because that gap is where paper alpha disappears.
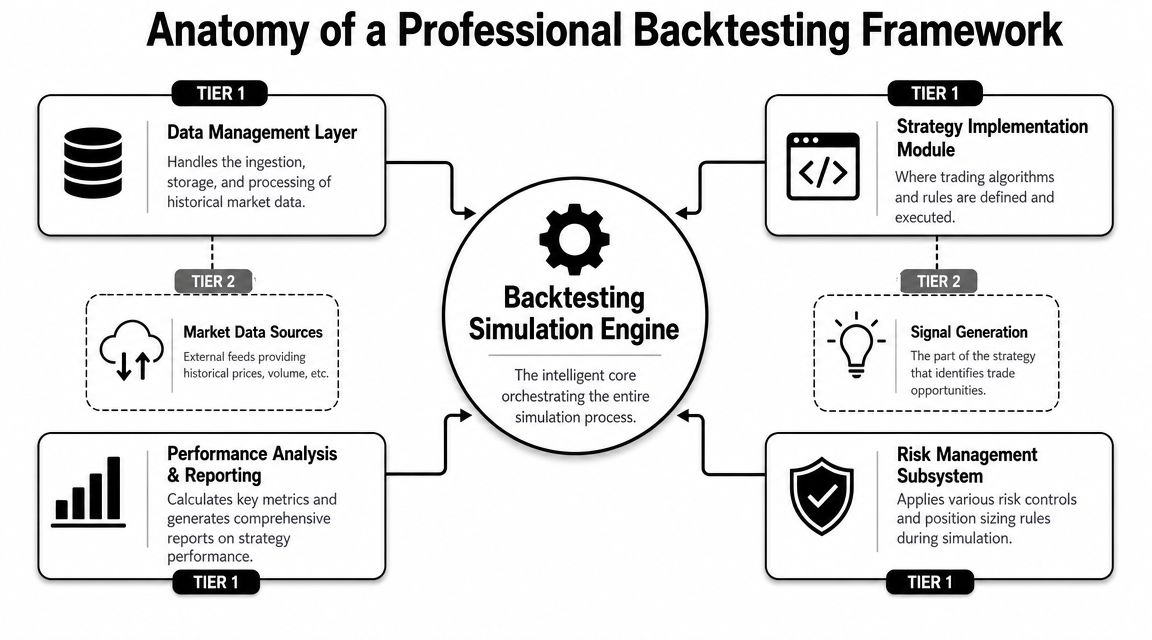
A serious framework behaves like a controlled replay of the actual trading stack. It does five jobs in sequence, and each one needs clear boundaries.
| Component | What it does | What breaks without it |
|---|---|---|
| Data ingestion | Pulls, normalizes, and timestamps historical market and on-chain records | Missing events, mixed schemas, chain-specific timestamp errors |
| Event engine | Replays observations in strict causal order | Lookahead bias, impossible sequencing, false signal timing |
| Strategy and signal layer | Turns observations into decisions using only current information | One-off logic, hidden future leakage, hard-to-repeat research |
| Execution model | Simulates routing, fills, gas, latency, slippage, and rejects | Unreal fills, ignored failed transactions, inflated returns |
| Portfolio and risk layer | Tracks positions, cash, exposures, fees, and constraints | Wrong PnL, broken sizing, no capital realism |
Weak frameworks usually fail in the middle. Data gets loaded. Reports get exported. A significant problem is that order timing, execution quality, and state updates are treated as approximations instead of first-class parts of the simulation.
Backtests that replay end-of-bar prices are fine for rough research on slow strategies. They are not enough for DeFi execution research.
On-chain systems are event-driven by nature. Blocks arrive. Mempool conditions change. A wallet trades. An indexer detects it. A parser classifies the event. The strategy decides whether to act. The execution layer estimates route quality and gas. The portfolio changes only if the transaction lands. If the framework skips any of those steps, it starts grading the strategy on information the live system would not have had.
That distinction matters most in copy trading, wallet following, and reactive flow strategies. Those strategies do not fail because the signal was always bad. They fail because the framework assumed immediate observation, immediate routing, and clean fills in pools that would not support them.
A clean architecture usually follows this path:
The difference between a research toy and a tool you can trust is usually operational discipline.
Good frameworks preserve raw event history and store the transformed version separately, so a suspicious fill can be traced back to the original swap, transfer, or contract call. They separate signal logic from execution logic, which makes it possible to answer a hard but useful question: did the idea fail, or did the execution assumptions fail?
They also support chain-specific custom data. Generic OHLCV pipelines do not capture router paths, pool reserves, token taxes, failed transactions, contract upgrades, or metadata fixes. DeFi research needs all of that. It also needs disciplined preprocessing. Teams that skip this step end up testing strategies on patched datasets they can no longer audit. For practical patterns, see filtered, replayable datasets for scalable backtesting systems.
One rule saves a lot of wasted research time.
Practical rule: If the framework cannot show what the strategy knew, when it knew it, what order it sent, and why that order did or did not fill, the backtest is not decision-grade.
Traditional backtests usually struggle with slippage, costs, and regime changes. DeFi adds another layer of pain. You're not only modeling price behavior. You're modeling chain behavior, transaction behavior, and pool behavior.
Most backtesting content focuses on generic price tests, but DeFi copy-trading needs event-level realism around wallet selection, token liquidity, gas fees, MEV and sandwich risk, and copy delay. The central issue is whether mirroring a profitable wallet remains profitable after those frictions are included across ecosystems like Ethereum, Solana, and Base, as discussed in the portfolio optimization book's section on backtesting dangers.
On-chain data looks rich until you try to use it for simulation. Then the problems show up.
You have duplicate decoded events from different pipelines. Missing token metadata. Contract upgrades that change behavior. Inconsistent timestamps between block inclusion and your indexed feed. Occasional reorg effects that make a clean historical sequence messy.
If your framework doesn't preserve provenance, you won't know whether a trade came from a stable source or a patched record. That matters because backtests often fail subtly. The PnL looks plausible, but the event chain underneath it is corrupted.
A practical response is to store multiple timestamps and keep the raw event payloads. You want block time, observed time, and simulated decision time. Those are different things.
The hardest part of DeFi backtesting isn't finding the signal. It's deciding what your execution model is allowed to assume.
Here's the minimum set of frictions a serious framework should model:
| Challenge | Impact on Strategy | Mitigation in Framework |
|---|---|---|
| Gas fee variation | Can erase small edge and change trade viability | Attach chain-aware cost models to each order event |
| MEV and sandwich risk | Worsens execution price beyond quoted levels | Apply adverse price movement assumptions on vulnerable routes |
| Copy delay | Late entry reduces or eliminates expected edge | Simulate detection, decision, submission, and confirmation as separate steps |
| Thin liquidity | Larger orders move the market and distort fills | Use pool state and liquidity-aware fill logic |
| Failed or dropped transactions | Strategy may miss exits or entries entirely | Allow order rejection and non-fill states in the simulator |
| Reorgs and data revisions | Historical ordering may change | Keep replayable raw data and support event correction |
| Survivorship bias in wallets | You end up testing only the winners | Freeze wallet selection rules at the historical decision point |
That last one gets ignored constantly. Traders often build a universe from wallets that are known winners today, then test that same list in the past. That's not research. That's a filtered survivor set.
For broader context on cleaning and organizing chain data before it reaches the simulator, see blockchain data analytics workflows.
Ethereum, Solana, and Base don't behave the same way operationally. Confirmation flow, fee behavior, routing assumptions, and congestion patterns differ. If your framework applies one execution template to every chain, you're smoothing away the very frictions that decide whether copy-trading works.
A professional approach uses chain-specific adapters with a shared interface. The strategy layer should stay portable. The execution layer should not.
A lot of DeFi backtests are really signal tests wearing execution costumes.
That distinction matters because a good signal can still produce a bad strategy if the chain-level friction is large enough.
The easiest way to judge a backtesting framework is to follow one trade from idea to post-trade analysis. If the workflow gets fuzzy at any point, the architecture is still too loose.
A clean process looks like this:

Start with a signal hypothesis. A tracked wallet buys a newly active token, and your strategy only mirrors trades when the wallet passes your historical quality filters and the token passes your liquidity rules.
The framework then moves through a strict sequence:
Signal intake
The engine receives a wallet event and tags the exact observation time.
Eligibility check
It confirms the wallet belongs to the approved universe and the token meets marketability requirements.
Execution snapshot
It estimates what route, fees, and fill conditions were available at your decision time, not at the wallet's transaction time.
Order simulation
The execution model decides whether the order fills, partially fills, drifts, or fails.
Portfolio update
Position, cash, fee accounting, and risk limits are updated.
Exit logic
The same framework later processes sell conditions, time-based exits, or wallet-driven unwinds.
Attribution
Reporting separates signal quality from execution drag.
That last step is where a lot of insight comes from. You want to know whether the idea failed because the wallet wasn't predictive, or because your execution assumptions made it untradeable.
Some teams start simple and some build for scale from day one. Both can work if the boundaries are clean.
| Architecture | Best for | Limits |
|---|---|---|
| Research-first Python stack | Fast iteration and custom experiments | Can become brittle if you bolt on live-trading features later |
| Service-oriented event engine | Multi-chain simulation and larger research pipelines | Higher engineering overhead upfront |
If you want a practical complement to this workflow from the discovery side, tools like a crypto arbitrage scanner can help generate hypotheses, but the framework still has to answer whether a historical signal survives realistic execution.
A walkthrough is easier to grasp visually, and this video covers the broader research-to-testing cycle:
A robust workflow logs every state transition. Not just orders and fills, but also rejected signals, invalid wallets, skipped tokens, and risk-based overrides.
Without that audit trail, debugging turns into guesswork. You can see that the strategy made money or lost money, but you can't explain why one candidate trade was accepted and another was filtered out.
The framework should let you replay a losing trade with enough detail to decide whether the model was wrong, the data was wrong, or the execution assumptions were wrong.
A new DeFi strategy can look excellent right up to the moment you add the parts that live trading will force on you. Gas spikes. A swap reverts because the pool moved. The entry you marked at the block close was never realistically available once you account for mempool competition and execution order. That is the point where a neat research script stops being useful and a real framework starts earning its keep.
It is often more practical to adapt an existing framework than to build a full engine from scratch, especially early on. The first goal is not architecture purity. It is proving that your assumptions are explicit, your tests are repeatable, and your results survive contact with ugly data and ugly execution.
Adapting an existing Python stack makes sense when your advantage sits mostly in signal logic, portfolio rules, or research speed. You get scheduling, parameter sweeps, and reporting without spending months writing plumbing you may later throw away.
A custom engine makes sense when the edge depends on market structure that generic tools do not model well. DeFi hits that boundary quickly. Wallet sequencing, failed transactions, nonce conflicts, chain reorg handling, gas-aware order selection, liquidity that changes inside a block, and MEV-sensitive fills are not small details. They can decide whether a strategy exists at all.
A practical rule is simple:
That last point matters. I have seen teams write a lot of infrastructure to avoid admitting they still had not defined the strategy clearly.
A polished dashboard does not make a framework credible. Before using one for decision-making, check whether it handles the failure cases that break DeFi research in practice.
Metrics still matter, but I treat them as the output of a sound process, not proof by themselves. A framework should report returns, drawdowns, hit rate, profit factor, turnover, cost breakdown, and exposure cleanly. For DeFi, I also want gas spent, failed transaction count, and performance with and without optimistic fill assumptions. If those toggles produce wildly different results, the strategy is probably more execution-sensitive than the headline PnL suggests.
Overfitting is still the default failure mode. DeFi just gives it more places to hide.
A researcher can tune entry filters, wallet cohorts, token exclusions, slippage tolerances, holding periods, and gas thresholds until the past looks convincing. Then live trading arrives and the edge disappears because the backtest was really measuring one temporary routing pattern or one unusual period of chain activity.
CME's paper on backtesting and statistical validity is useful here because it focuses on model selection bias, not just headline Sharpe. The practical lesson is straightforward. The more variants you test, the less faith you should place in the best one.
For a first framework, I would rather see modest reporting with strict assumptions than beautiful analytics built on impossible fills. A basic engine that handles timestamps correctly, preserves causality, charges realistic costs, and records failed execution is more valuable than a feature-rich platform that implicitly assumes every swap goes through at the quoted price.
That is the line between a toy model and a tool you can actually trust with capital.
A backtesting framework only tells the truth about the ideas you feed into it. If your input set is random wallets, stale token lists, or cherry-picked screenshots, the engine won't rescue you.
The better workflow starts with structured signal discovery. Instead of handpicking a wallet because one trade looked impressive, you build a candidate universe from observable behavior and export that history for offline testing.
One workable approach is:
Filter wallets by behavior
Start with wallets that fit your strategy style, such as short holding periods, repeat entries in new listings, or selective concentration.
Inspect trade history manually
Look at entry timing, exit discipline, and whether the wallet tends to buy into strength or before momentum becomes visible.
Export the event history
Pull the wallet's transactions and use them as input data for your own simulation environment.
Freeze the selection rule historically
Don't select today's winners and pretend you knew they were winners in the past.
Replay under your constraints
Apply your own position sizing, rejection rules, and execution assumptions.
Wallet Finder.ai can fit into that workflow because it surfaces profitable wallets, trades, and token histories across major chains and allows data export for offline analysis. Used that way, it's not the strategy. It's the research input.
A good wallet candidate usually has characteristics you can model:
If the wallet only looks good when you assume perfect synchronization and perfect fills, it isn't a reliable signal source. It's a highlight reel.
A serious backtesting framework does one thing extremely well. It removes fantasy from strategy research.
That matters even more in DeFi than in other markets because wallet-based strategies live and die on sequencing, gas, liquidity, latency, and chain-specific execution. If your framework ignores those details, it won't protect you from bad deployment decisions. It will encourage them.
The practical goal isn't to build a flawless model. It's to build a process that catches weak assumptions early, tests ideas under realistic conditions, and produces results you can audit trade by trade. That's what turns wallet mirroring from speculation into research.
The traders who last in this market usually don't have the prettiest equity curves in backtest screenshots. They have better simulation discipline, better data hygiene, and stricter standards for what counts as tradable edge.
If you want cleaner inputs for wallet-based strategy research, Wallet Finder.ai gives you a structured way to discover wallets, inspect trade histories, and export data for offline testing inside your own backtesting framework.

A premier DeFi analytics platform empowering traders to discover and analyze profitable blockchain wallets, trades and tokens.

