
Recovery Factor Calculation for Smart Traders
Master the recovery factor calculation to measure a strategy's resilience. Learn the formula, see DeFi examples, and find top wallets with Wallet Finder.ai.

June 20, 2026


Wallet Finder
April 29, 2026
Manual trading usually breaks at the same point. You catch a wallet buy on-chain, open a centralized exchange, check liquidity, and by the time you click through the order ticket the move is already underway. The problem isn’t just speed. It’s consistency, repeatability, and the ability to turn signals into execution without rebuilding the same workflow every hour.
That’s where crypto exchange apis stop being a developer concern and become trading infrastructure. If you’re building a copy trading system, a PnL tracker, a market scanner, or a research pipeline that blends on-chain activity with exchange liquidity, the API layer is the system. Bad integration creates stale prices, missed fills, duplicate orders, and account risk. Good integration gives you clean data, predictable execution, and logs you can trust when something goes wrong.
The practical challenge is that exchange APIs are never just about endpoints. They force decisions about transport, authentication, rate limiting, retries, schema normalization, and where your strategy should run. Most generic guides stop at “use REST for data and WebSockets for real-time updates.” That’s not enough if you’re trying to mirror wallet activity across Ethereum, Solana, and Base while routing execution through one or more CEX venues.
This guide takes the builder’s view. It focuses on what works in production, what fails under volatility, and how to design a system that turns market data plus on-chain signals into actions you can automate.
A wallet you track buys on-chain. Seconds later, the same token starts moving on a centralized exchange, spreads tighten, and liquidity shifts across venues. If your system cannot read that change, compare it against account risk, and send an order fast enough to matter, the signal has little trading value.
Exchange APIs sit at the center of that workflow. They feed market data into scanners, route orders into matching engines, return fills for PnL analysis, and expose balances and positions for risk checks. For copy trading in particular, the API layer decides whether a wallet signal becomes a controlled trade or a late entry with poor execution.
That infrastructure is now broad enough that teams do not need to wire every venue from scratch. According to ChangeHero’s roundup of crypto exchange APIs, leading aggregators cover 100,000+ coins across 200+ exchanges and 10,000+ DeFi protocols. The same source says projections for 2026 pointed to live WebSocket coverage for the top 12 exchanges. The point is not the exact count. The hard part is fragmentation. Each exchange uses different symbols, payload formats, precision rules, and timing behavior, which means integration work still decides whether the system is dependable under load.
A trading application usually needs several API surfaces working together:
The harder problem starts when CEX data has to be combined with wallet activity on-chain. A useful system does more than detect a wallet buy. It checks whether the move is already reflected in the order book, whether size can be copied without heavy slippage, and whether the trade still fits portfolio and exposure limits. That is the difference between signal collection and actual execution logic.
Practical rule: If your API flow cannot take an on-chain event, price it against live exchange liquidity, and return a tracked order state, the strategy is still only partially automated.
The systems that hold up during volatility tend to share the same design choices:
| Requirement | Weak implementation | Dependable implementation |
|---|---|---|
| Market data | Repeated polling | Stream first, poll only for recovery |
| Order handling | Fire-and-forget submissions | Full order lifecycle tracking |
| Security | One key for everything | Separate scoped keys by use case |
| Exchange support | Venue-specific code everywhere | Normalization layer or wrapper |
| Failure recovery | Manual restarts | Retries, reconciliation, and alerts |
Those choices affect trading results directly. Missed sequence numbers produce bad local books. Loose order tracking creates duplicate submissions. Poor key separation turns one leaked credential into an account-wide incident. Good API integration is not just engineering hygiene. It is part of execution quality, risk control, and trustworthy PnL.
The first architectural choice isn’t strategy logic. It’s transport. In practice, most production systems use both REST and WebSocket APIs, but they use them for different jobs.
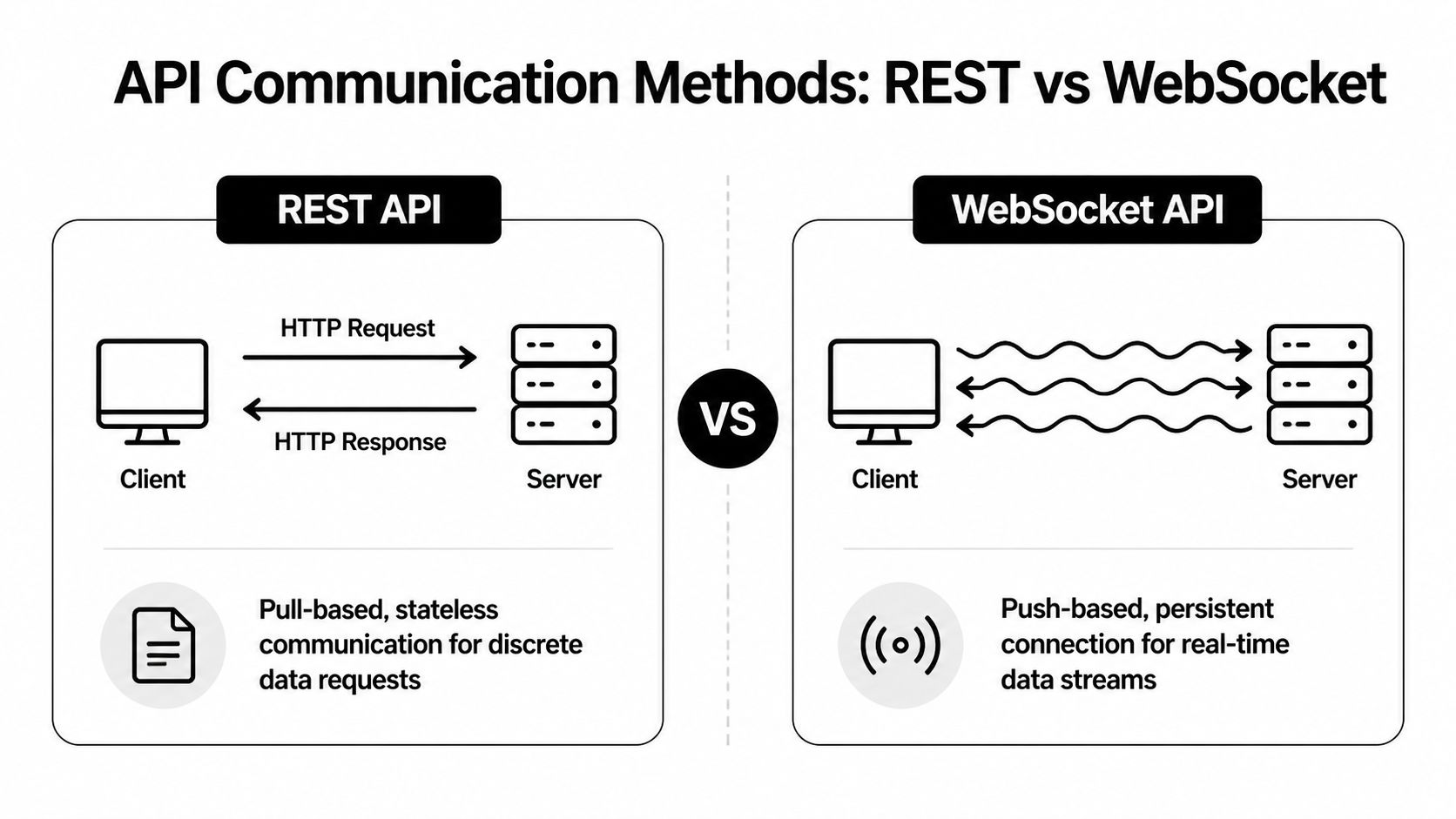
REST is request-response. Your application asks for something, the exchange sends back a result, and the connection ends. That model is easy to reason about and easy to test.
Use REST when you need to:
REST is also where many teams start because the tooling is familiar. You can inspect payloads, replay requests, and build a clean client library around the exchange’s endpoints.
The downside is obvious once a strategy becomes time-sensitive. Polling for order book changes or recent trades is inefficient and eventually hits rate limits. You also create uneven visibility because your app only sees the market when it asks.
A WebSocket stays open. The server pushes updates to you as they happen. That’s the right model for order books, live trades, and user events such as fills or cancels.
Use WebSockets when you need:
For copy trading and wallet mirroring, WebSockets are usually the difference between reacting to a move and trailing it. If your system waits for repeated REST calls to discover price changes, it’s already late.
| Characteristic | REST API | WebSocket API |
|---|---|---|
| Communication model | Request-response | Persistent two-way connection |
| Best use | Historical data, account checks, order submission | Live trades, order books, user events |
| Latency profile | Higher for repeated updates | Lower for continuous streams |
| Rate limit pressure | High if used for polling | Lower when streams replace polling |
| Simplicity | Easier to start with | Harder to operate correctly |
| Failure mode | Missed updates between requests | Disconnects, stale streams, resync issues |
WebSockets reduce polling, but they add state management. You need heartbeat handling, reconnect logic, sequence validation, and book resynchronization after drops. REST is simpler, but simplicity disappears when you try to brute-force real-time behavior through polling.
Use REST for control paths. Use WebSockets for time-sensitive state.
That split keeps your design sane. Historical candles, symbol metadata, and order placement can stay in a conventional client. Streaming books, trades, and account events should run in an event-driven pipeline.
If your strategy can place trades, your API keys are operational funds access. Treat them like private keys, because the practical risk is similar. One leaked key with broad permissions can wipe out a trading account long before anyone notices.

The baseline security model is already well established. Crypto APIs’ standards and conventions documentation ties secure exchange API practice to IEEE 2140.5-2020 and ISO/TR 23576:2020, including HTTPS-only transmission, permission-scoped keys, and strict request timing, with exchanges often enforcing a ±5-second window on signed requests. That timing detail matters more than many teams expect. Clock drift can make valid requests fail, and retry logic can create duplicate actions if you don’t design around it.
One of the easiest mistakes is creating a single master key for every workflow. Don’t.
A safer setup looks like this:
Exchanges such as Kraken also support controls like 2FA, IP whitelisting, and permission-scoped keys. Those aren’t optional extras for serious systems. They’re part of your blast-radius reduction plan.
Private endpoints usually require your client to sign each request with a secret. The exact signature payload varies by exchange, but the pattern is consistent.
Two operational rules matter here. First, your application clock must stay synchronized. Second, retries must be idempotent where possible, so a network timeout doesn’t create accidental duplicate orders.
A good key policy is boring by design:
This walkthrough gives a decent visual overview of API credential handling before you automate anything live:
A trading stack usually fails on security through convenience. Someone hardcodes a key, reuses it across services, or grants permissions “temporarily” and never removes them.
| Practice | Why it matters |
|---|---|
| IP whitelisting | Limits where requests can originate |
| Permission-scoped keys | Contains damage if a key is exposed |
| Clock synchronization | Prevents replay rejection and auth failures |
| Regular rotation | Reduces exposure window |
| Separate keys per workflow | Stops analytics or reporting services from inheriting trade access |
The best security posture is simple: assume a service will eventually fail, then make sure the credentials attached to it can’t do much damage.
A bot can have good signals, clean auth, and solid order logic, then still fail because its data plane falls apart under load. That failure usually starts with avoidable request patterns. A worker polls too often, retries in sync with every other worker, or burns request budget on endpoints that do not affect trading decisions.

OpenWare’s discussion of crypto exchange API integration challenges highlights the pattern clearly. It cites an analysis projecting that by 2026, a large share of trading bot failures would come from unoptimized API polling, and it notes that some platforms enforce limits as low as 10 requests per second. The practical lesson is simple. REST is for snapshots, reconciliation, and recovery. It is a poor substitute for a live event stream.
Polling gets expensive fast in multi-strategy systems. One service asks for balances every second. Another refreshes open orders. A third checks ticker data across dozens of pairs. Add copy trading logic that watches a source account on a CEX while also tracking related wallet flows on-chain, and the pressure multiplies. If those services are not coordinated, they compete for the same request budget and create stale state at the worst possible moment.
A workable design uses three lanes:
If you want a more detailed reference, this guide on API rate limit strategies for crypto apps covers the control patterns that keep traffic predictable.
The biggest improvements rarely come from shaving a few milliseconds off JSON parsing. They come from removing waste and isolating critical paths.
| Failure point | Better design choice |
|---|---|
| Repeated REST polling from multiple services | Central request scheduler with shared cache |
| Full state rebuild after every reconnect | Incremental stream processing plus periodic checksum or snapshot validation |
| Retry storms after 429s or timeouts | Exponential backoff with jitter and per-endpoint budgets |
| Analytics jobs competing with execution traffic | Separate queues and credentials for trading, reporting, and research |
| Strategy code waiting on network calls | Event-driven ingest layer feeding internal state stores |
One-sentence rule: protect order placement traffic before anything else.
Sleep-based throttling works in a toy script. It breaks in production because exchanges assign different weights to different endpoints, change quotas, and enforce limits across IPs, accounts, or API keys.
Use adaptive throttling instead. Track request cost by endpoint, maintain rolling counters, and shed low-priority work before the exchange starts rejecting calls. For example, if a copy trading engine is syncing fills from a centralized exchange and also enriching those fills with wallet activity from an EVM indexer, trade execution and account updates should keep their budget. PnL backfills and wallet-label refreshes can wait.
The last item matters more than many teams expect. Low latency is useful. Fresh state is what protects PnL.
For advanced strategies, performance also means matching two clocks. The CEX side tells you where you can execute and at what depth. The on-chain side tells you which wallets are accumulating, distributing, or routing flow before it becomes obvious in exchange prints. If API limits delay either side, the combined signal degrades. Copy a wallet too late and you inherit worse entry. Attribute PnL on stale fills and your strategy evaluation drifts away from reality.
Public market data is the raw material for almost everything else. If the feed is incomplete, delayed, or poorly normalized, your strategy logic, PnL attribution, and execution assumptions all degrade.
Most applications depend on three public data categories.
Tickers are snapshots. They usually provide a current price, a recent change view, and a volume summary. They’re useful for scanners, watchlists, and broad market dashboards.
Tickers are not enough for execution decisions. They don’t tell you how much size the market can absorb, how the book is shaped, or whether a move is being driven by actual prints.
The order book is where execution logic becomes informed. It shows resting bids and asks, which lets you estimate spread, depth, and likely slippage.
For copy trading, the book matters more than the last traded price. A wallet can buy a token on-chain with one liquidity profile while the centralized venue shows a very different depth profile. If you mirror off the last price alone, your expected fill quality is mostly guesswork.
Historical OHLCV data gives you context for research, backtests, and signal filters. Historical trade data is even more useful when you care about microstructure, but candles are often enough for strategy prototyping.
If you’re comparing venues or validating broad price behavior, a separate market data provider can reduce a lot of effort. This overview of an API for crypto prices and market feeds is useful when you need broader coverage than a single exchange provides.
A clean market data stack often looks like this:
REST for startup state
WebSocket for live state
Periodic reconciliation
| Data type | Best transport | Common use |
|---|---|---|
| Ticker | REST or WebSocket | Watchlists, broad scanners |
| Order book | WebSocket | Slippage checks, execution logic |
| OHLCV candles | REST | Backtesting, indicators |
| Public trades | WebSocket | Momentum, tape, microstructure |
Don’t use a ticker endpoint as a substitute for book data. Don’t backtest off one venue’s candles and assume another venue will execute similarly. And don’t trust a streaming book unless you can detect gaps and rebuild it.
Clean data doesn’t just improve research. It prevents execution mistakes that look like strategy mistakes.
Reading market data is the easy half. Trading through APIs is where small mistakes become financial errors. Order type selection, signing, retries, and order-state reconciliation all matter more than the initial create_order call.
A market order is useful when urgency matters more than price precision. It’s simple, but in thin books or fast moves it can fill worse than expected.
A limit order gives price control. That makes it the default choice when you care about slippage or want to join liquidity. The trade-off is obvious. The order may sit partially filled or not fill at all.
Conditional orders vary by venue, but the intent is consistent:
A capable bot doesn’t treat order submission as the end of the task. It tracks the entire lifecycle:
If you skip reconciliation, you eventually trade on stale assumptions. That’s how bots double-enter, fail to exit, or size a new order using a position that no longer exists.
| Risk | Guardrail |
|---|---|
| Duplicate order on retry | Client order IDs and idempotency design |
| Rejection from precision rules | Local validation against exchange filters |
| Stale position state | User data stream plus periodic reconciliation |
| Slippage on urgent entries | Pre-trade book check and size caps |
| Hanging open orders | Timeout policy and cancellation routine |
Many teams write a thin exchange adapter that normalizes a few concepts across venues:
place_limit_orderplace_market_ordercancel_orderget_open_ordersget_position_stateThat works better than exposing the raw exchange schema everywhere in your codebase. Keep the strategy thinking in normalized concepts, and isolate exchange quirks inside the adapter.
A final caution matters here. Never let “temporary” execution shortcuts survive into production. If your code can’t prove whether an order filled, it can’t manage risk.
Margin and derivatives endpoints look similar to spot APIs on the surface, but the risk model is different enough that they deserve their own controls. You’re no longer just buying or selling an asset. You’re managing borrowed capital, collateral, liquidation risk, and contract-specific behavior.
The API surface expands in a few important ways:
That means the execution engine can’t just “reuse spot code” and call it done.
A safer derivatives workflow usually includes:
| Failure point | Why it hurts |
|---|---|
| Assuming spot and perp symbols map cleanly | Contract naming often differs |
| Ignoring funding and margin state | Carry and exposure can drift |
| Using market orders blindly | Slippage compounds under leverage |
| Missing partial liquidation signals | Position state can change before your strategy reacts |
With leveraged APIs, every weak assumption gets magnified. A stale balance view on spot is annoying. A stale margin view can become a liquidation problem.
If you trade derivatives through APIs, keep the risk engine close to the execution engine. Don’t separate them into unrelated services that communicate lazily. Position state, collateral state, and order state need tight reconciliation. If they drift apart, your strategy logic can be technically correct and still operationally dangerous.
Writing every exchange connector by hand is rarely the best use of engineering time. The better question is where abstraction helps and where it creates blind spots that hurt execution, monitoring, or reconciliation later.
Official SDKs are a good fit when one venue matters more than portability. They usually handle signing, timestamp formatting, endpoint models, and version updates with less friction than a custom client. That saves time on setup and reduces avoidable mistakes in authentication code.
Multi-exchange wrappers such as CCXT fit a different job. They are useful for research systems, market scanners, and early-stage bots where the goal is to compare venues quickly without building five separate adapters first. For normalized tasks like fetching markets, balances, tickers, and basic order types, that trade-off is often worth it.
The catch is predictable. Exchange-specific behavior still leaks through the abstraction layer. Conditional orders, client order IDs, trigger price rules, post-only handling, and settlement asset conventions often differ enough that a wrapper gives you a common interface but not identical behavior. Teams usually discover that during production incidents, not during backtests.
Aggregators solve a different problem. They are better for coverage than for execution.
If the system needs broad market discovery, historical reference data, or cross-venue monitoring, an aggregator can simplify the pipeline a lot. Instead of polling dozens of exchange APIs just to answer basic questions about listings, prices, or market availability, one data provider can feed the research layer while direct exchange connections stay focused on trading.
That separation is useful in hybrid strategies built around wallet tracking. An on-chain watcher might flag a token because a smart wallet accumulated it on DEXs, but the execution service still needs to answer practical questions fast: Is the asset listed on a liquid CEX, which symbol maps correctly, and do venue prices diverge enough to justify acting? Aggregator data helps triage those questions before the strategy commits more expensive exchange-specific calls.
If you want a practical reference for that workflow, this guide to CoinGecko API documentation for crypto data workflows shows how developers use an aggregator feed for discovery and analytics.
| Need | Better fit |
|---|---|
| Single-venue execution with venue-specific features | Official SDK or direct client |
| Multi-venue prototyping | CCXT or similar wrapper |
| Broad market discovery and analytics | Aggregator API |
| Low-level control over exchange edge cases | Direct exchange integration |
SDKs and aggregators reduce plumbing. They do not remove responsibility for correctness.
Production systems still need exchange-aware validation, retries with backoff, idempotent order handling, symbol mapping checks, and post-trade reconciliation. For copy trading and PnL analysis, this matters even more. If your on-chain signal says a target wallet bought an asset, but your CEX adapter maps the wrong market, rounds size incorrectly, or lags on fill status, the strategy can look right in theory and lose money in practice. Use abstractions to speed up integration. Keep the hard parts close to your own control.
The most useful pattern for advanced crypto systems is a hybrid one. Let on-chain activity generate the signal, then let centralized exchange infrastructure handle validation and execution. That gives you early intent from smart wallets and better trade mechanics where books are deeper and execution is easier to automate.
The architecture that supports this pattern has to be deliberate. This practical guide to crypto exchange architecture describes an effective model built around microservices, an API Gateway for authentication and rate limiting, an Order Management System, and WebSocket feeds for real-time price updates, enabling sub-100ms latency on high-volume workflows. That’s the right shape for a system that ingests on-chain events and reacts on a CEX quickly enough to matter.
At a high level, the flow looks like this:
That sequence sounds simple. The edge cases are not.
The on-chain token identifier rarely maps cleanly to a CEX symbol without a maintained reference layer. Wrapped assets, migrated contracts, and exchange naming quirks can all produce false matches.
On-chain timestamps, exchange event timestamps, and your own internal processing timestamps need to be comparable. If they aren’t, your replay analysis becomes unreliable and your live strategy can react to stale signals.
A wallet may execute into a DEX pool that supports the trade, while the token’s CEX market has weak depth or wide spreads. If your copy engine doesn’t check the book, it can chase the signal into bad execution.
| Service | Primary responsibility |
|---|---|
| Signal ingestion | Capture wallet buys, sells, and swaps |
| Asset normalization | Map token contracts to tradeable symbols |
| Market data | Maintain exchange books and trades |
| Execution | Submit, cancel, and reconcile orders |
| Risk engine | Enforce sizing, exposure, and venue rules |
| PnL and analytics | Attribute fills and evaluate signal quality |
Don’t copy every wallet action. Score it.
Useful filters often include:
That’s where a lot of generic crypto exchange apis content falls short. It talks about data access and order entry, but not about the middle layer where on-chain intelligence becomes a constrained execution decision.
The best hybrid systems don’t “mirror trades.” They translate signals into venue-aware execution plans.
A few hard rules make these systems much safer:
You get earlier discovery from wallets, cleaner execution on centralized books, and far better observability than trying to trade directly from fragmented manual workflows. You also get a system you can audit. That matters when performance changes and you need to know whether the issue came from the wallets you track, the exchange feed, the order router, or your own risk filters.
The result is not “automatic alpha.” It’s something more useful. A pipeline that can consistently turn external signals into structured decisions, then into orders, then into measurable PnL.
Wallet tracking is only useful if you can act on it. Wallet Finder.ai helps traders identify profitable wallets across ecosystems like Ethereum, Solana, and Base, inspect full trading histories, monitor PnL and entry timing, and receive real-time alerts when tracked wallets move. If you’re building or refining a hybrid workflow that combines on-chain signals with exchange execution, it’s a practical way to surface the signals worth routing into your trading stack.

A premier DeFi analytics platform empowering traders to discover and analyze profitable blockchain wallets, trades and tokens.

