
Recovery Factor Calculation for Smart Traders
Master the recovery factor calculation to measure a strategy's resilience. Learn the formula, see DeFi examples, and find top wallets with Wallet Finder.ai.

June 20, 2026


Wallet Finder
June 20, 2026

You're probably staring at a wallet leaderboard right now, trying to answer a simple question that never stays simple for long: who's worth copying?
One wallet shows a huge realized gain. Another has a clean win streak. A third caught a token before it exploded, and now it looks like a genius. Then you copy the next move, and suddenly the magic disappears. The wallet that looked elite was really just loud. One big trade made the profile sparkle, but the behavior underneath it wasn't stable.
That's the problem with reading on-chain performance the way most traders read it. They chase signal size instead of signal quality.
A reliability ranking fixes that. It gives you a way to separate traders who got paid once from traders who repeatedly make decisions you'd want to mirror. It's less about “who had the biggest win” and more about “who behaves in a way that keeps making sense across time, volatility, and different market conditions.”
If you already compare wallet results against a broader performance benchmark for trading evaluation, you're halfway there. The next step is asking whether that performance is repeatable enough to trust with your capital.
A lot of copy traders learn the same lesson the expensive way.
You find a wallet that turned a small position into a massive gain on one meme coin or early rotation. The trade history looks sharp. The PnL column grabs your attention. You tell yourself that if this trader found one rocket, they'll find the next one too.
Then the next few trades look very different.
The entries come late. The sizing gets erratic. The wallet starts chasing thin liquidity, averaging down into weak names, or flipping too fast for your own execution to keep up. You copied the highlight reel, not the actual process.
PnL is useful, but it's incomplete. It tells you what happened, not how dependable the behavior is.
A wallet can post strong gains because of:
That's why two wallets with similar profit can be very different trading signals.
One trader may scale into setups in a consistent way, cut losers, and stay inside a recognizable playbook. Another may look profitable only because one position hit hard enough to erase a string of weak decisions.
Practical rule: If you can't explain how a wallet usually wins, you shouldn't assume it will keep winning.
Copy trading adds extra friction. You aren't just evaluating a strategy. You're evaluating whether you can follow it in real time.
A wallet might be profitable yet still be hard to copy because:
A reliability ranking helps because it shifts your attention from dramatic outcomes to repeatable habits. That gives you a cleaner answer to the question that matters: is this wallet likely to remain useful after I start following it?
You pull up two wallets before a trade. Both show strong profit. One wallet has a jagged history with a few explosive wins. The other keeps producing decent entries, controlled losses, and a style that looks familiar week after week. If you are deciding what to copy with real money, those are not equal signals.
A wallet reliability ranking is a structured score that estimates how trustworthy a wallet's trading behavior is over time.
The key idea is simple. Raw profit tells you what happened. Reliability helps you judge whether that result came from a repeatable process you can use. For an on-chain trader, that difference matters because copied trades only pay if the wallet keeps behaving in a way you can recognize and act on.
Consider the difference between a casino hot streak and a card counter with a method. Both can leave the table up money. Only one gives you a reason to expect the next session will resemble the last. A reliability ranking tries to separate those two cases on-chain.
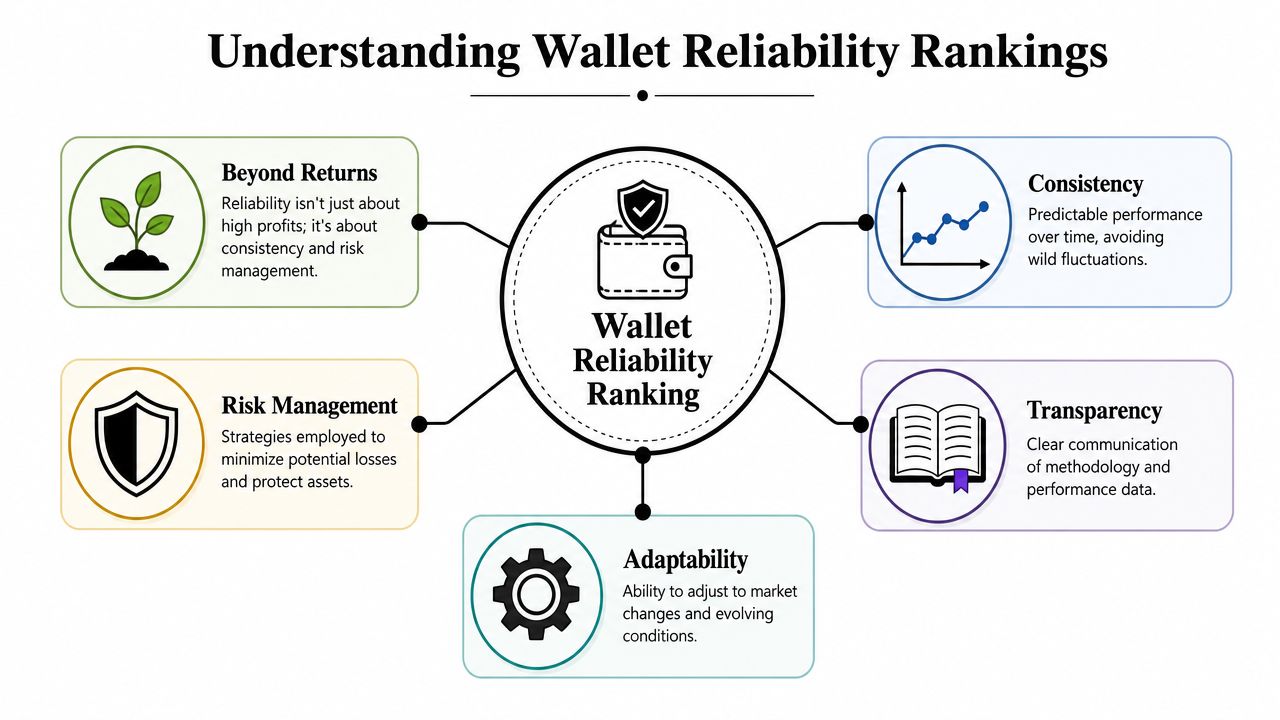
For traders, reliability is less about perfection and more about signal clarity.
If a wallet enters similar setups, manages risk in a recognizable way, and avoids wild swings in behavior, its history gives you a cleaner read on what to expect. If the wallet jumps between styles, depends on a few outlier wins, or hides long weak stretches behind one lucky run, the signal gets noisy. The ranking should reflect that difference.
That is why a useful ranking is not just a score on a leaderboard. It is a filter for trust. You are asking whether the wallet's past activity forms a pattern strong enough to support future decisions with capital at risk.
On-chain trading is a messy system. Entry timing, token selection, volatility, liquidity, hold time, sizing, and market regime all shape the final PnL. A single stat flattens that story too much.
A better framework combines several inputs, then asks a practical question: does this wallet produce a signal that survives contact with real execution?
Monte Carlo's explanation of data reliability is useful here because it treats reliability as a function of whether downstream users can trust the output, not whether one visible metric looks fine. Wallet rankings should work the same way. The score should reflect the chance that following this wallet leads to stable decision-making, not just impressive screenshots.
For a copy trader, that usually means evaluating questions like these:
If you want the supporting inputs behind those questions, this guide to key metrics for identifying profitable wallets gives useful context.
A wallet reliability ranking is a multi-factor score that measures whether a wallet's behavior is consistent, interpretable, and practical enough to trust with real capital.
That definition matters because it connects statistics to trading action. You are not scoring a wallet for being interesting. You are scoring it for usefulness. A high-reliability wallet gives you a stronger base for copy trading, alerting, or using its activity as confirmation on your own setups.
In other words, reliability ranking turns raw wallet history into a decision tool. It helps you move from "this wallet made money" to "this wallet produces a signal I can trust."
If reliability ranking is the finished product, these are the ingredients.
The important shift is this: don't read wallet stats as isolated badges. Read them as clues about a trader's operating style. A wallet with decent returns and controlled losses often tells a better story than one with explosive gains and chaotic behavior.
For a wider view of these inputs, this guide to key metrics for identifying profitable wallets is a useful companion.
For physical systems, reliability frameworks often rely on failure and recovery measures such as mean time between failures and mean time to repair, because the most dependable assets are the ones that fail less often and recover faster, as outlined by the University of Tennessee's reliability metrics guidance. That's a strong analogy for trading. A reliable wallet isn't one that never takes a hit. It's one that limits damage and recovers in a disciplined way.
Here's a practical trader version of that logic.
| Metric | What It Measures | Why It Matters for Reliability |
|---|---|---|
| Win rate | How often trades close profitably | Helps reveal whether the wallet's edge shows up regularly, but it can mislead if winners are small and losers are large |
| PnL | Net trading outcome over the observed period | Shows whether the strategy actually made money, though it says little on its own about stability |
| Max drawdown | The deepest decline from a prior peak | Shows how painful the strategy can get while you're following it |
| Risk-adjusted return | Return quality relative to the volatility or downside taken | Separates disciplined profitability from reckless profitability |
| Trade frequency | How often the wallet enters and exits positions | Tells you whether the style matches your ability to execute and monitor |
| Position sizing consistency | Whether the wallet sizes trades in a stable, understandable way | Helps you detect discipline versus emotional or random sizing |
| Holding period behavior | How long positions are typically held | Distinguishes scalpers, swing traders, and conviction holders |
| Recovery pattern | How the wallet behaves after losses | Reveals whether bad periods are controlled or followed by revenge trading |
A few examples make this easier.
Good reliability signals are usually easy to describe in plain English:
Weak reliability signals also tend to be obvious once you know to look for them:
The cleanest wallet profiles often look a little boring. That's usually a feature, not a flaw.
Two wallets can post the same profit and still deserve very different levels of trust.
One gets there with steady sizing, controlled pullbacks, and repeatable entries. The other gets there from one oversized winner surrounded by messy execution. If you copy both the same way, your outcome will not be the same. That gap is the whole reason reliability scoring exists.
A useful ranking takes raw on-chain behavior and turns it into a score you can trade from. The hard part is not collecting data. The hard part is deciding what should matter more, what should matter less, and how to combine unlike signals without distorting them.
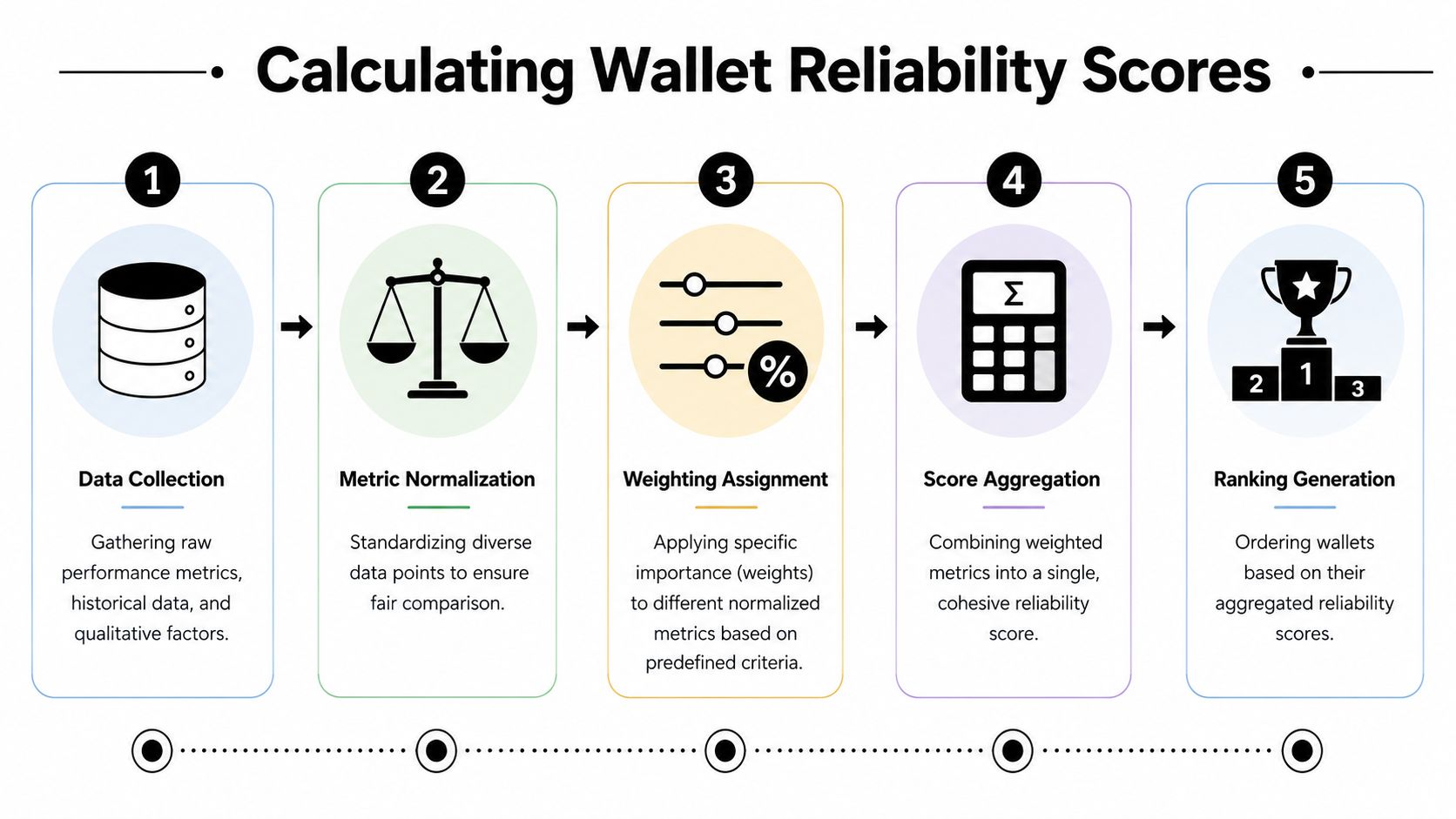
Start with the raw inputs. A wallet has returns, drawdowns, sizing patterns, trade timing, holding periods, and recovery behavior. Those numbers do not arrive in the same units, so you cannot stack them together and call the result meaningful.
The first step is normalization. That means putting different metrics onto a comparable scale so one large-number field does not overpower the others by accident. A wallet with high dollar PnL should not automatically outrank a smaller wallet if its behavior is far less repeatable.
Then comes weighting, during which the model reveals its priorities.
A practical process usually looks like this:
If you already have a workflow for evaluating traders, this should feel familiar. It works like a report card. Math, writing, and science all count, but they do not always count equally.
This is the part traders often miss.
A score is not objective just because it is numerical. The weighting scheme decides whether the leaderboard favors smooth operators, aggressive hunters, patient swing wallets, or high-frequency specialists. If you do not know the weighting, you do not know what first place means.
A conservative copy-trading model usually gives more weight to:
A more aggressive model may place more weight on:
Both can be valid. They just answer different questions.
One asks, "How safely can I follow this wallet?" The other asks, "How much upside has this wallet captured?" Those are related, but they are not the same.
It helps to group the inputs into buckets instead of staring at a long list of metrics.
A clean model might use four:
That last bucket matters more in on-chain trading than many ranking systems admit. A wallet can look brilliant on paper and still be hard to copy in real conditions if it trades too fast, enters too early, or scales in with a style followers cannot replicate. If you want a practical checklist for that layer, use this 5-step process for screening profitable wallets.
Say Wallet A and Wallet B both finished the quarter with strong returns.
Wallet A produced those returns with moderate trade frequency, similar position sizes, and shallow pullbacks. Wallet B posted the same headline result, but most of it came from one breakout trade after several unstable weeks and wider swings.
A return-heavy model might rank them close together.
A reliability-first model will usually separate them fast, because it cares about the path, not just the destination. For copy traders, the path is where slippage, hesitation, and bad timing turn a wallet's great result into your mediocre one.
Field check: If a wallet needs perfect timing or unusual risk tolerance to match its historical PnL, its reliability score should reflect that.
The final score should compress information, not hide it.
You should be able to see which factors pushed a wallet up, which factors held it back, and whether the score still makes sense if market conditions change. A ranking you cannot inspect is hard to trust because you cannot tell whether it rewards repeatable edge or just a lucky stretch.
That is the bridge from statistics to trading signal. Raw on-chain data becomes useful only after it is standardized, weighted, and checked against real execution constraints. Once that framework is clear, a reliability ranking stops being a decorative leaderboard and starts becoming a filter for protecting capital and finding wallets worth following.
The same high reliability score can point to very different wallet types. That's where many traders slip. They treat ranking as a final answer when it's really a filter.
Start by asking what kind of trader you are.
The active copier needs wallets with repeatable entries, manageable frequency, and enough holding time to act.
The swing trader can tolerate fewer trades if the setups are cleaner and the holds are longer.
The conviction follower may prefer a wallet that enters less often but sizes with intent and holds through noise.
The ranking helps you narrow the list. Your job is to decide whether the wallet's profile fits your own execution reality.
A few practical interpretations:
Ranking stability matters. Research on the “reliability gap” argues that a model can show strong predictive accuracy while still producing unstable rankings, which makes the ordering less dependable for real-world decisions, as noted in this ScienceDirect abstract on ranking stability. For copy traders, the takeaway is direct: a wallet's rank shouldn't just be high once. It should stay meaningfully high across time and different samples.
If you're reviewing candidates, use a short process like this:
A wallet that fits your process usually beats a wallet that only looks better on paper.
Most traders don't struggle because the idea of reliability is hard. They struggle because the raw on-chain data is messy.
You open a wallet, scroll through trades, spot a few great entries, then lose the plot. Was the sizing consistent? Did the trader recover well after a bad period? Was the profit concentrated in one stretch, or spread across many decisions? Answering those questions manually takes time.
This kind of platform view helps compress that work into something reviewable:
A practical workflow usually starts with discovery. You sort wallets by a mix of returns, consistency, and recent behavior, then narrow the pool by chain, timeframe, or trading style.
After that, you move from ranking to inspection:
Wallet Finder.ai is one tool that organizes wallet histories, PnL, trade timing, position sizing, filters, and alerts in a way that supports this kind of review. Used properly, it's less a magic list and more a workflow for turning raw wallet activity into a reliability judgment.
When you inspect a wallet, focus on a few questions:
Is the behavior coherent?
You want a recognizable style. If the wallet alternates between careful accumulation and random punts, the rank deserves more skepticism.
Do the recent trades match the old pattern?
A wallet that built its reputation one way and now trades differently may no longer deserve the same trust.
Can you operationalize the signal?
Alerts, watchlists, and exportable data matter because a useful ranking only pays you if you can act on it in time.
That's the fundamental difference between a theoretical reliability ranking and a trading one. A trading ranking has to survive contact with live execution.
A ranking can improve your decisions, but it can also make bad habits look more advanced.
The biggest mistake is blind obedience. Traders see a wallet near the top of a list and assume the hard thinking is over. It isn't. A high-ranked wallet can still be wrong for your capital, your timing, and your temperament.
Following the top wallet without reading the style
A fast trader with short holds may be impossible for you to copy cleanly, even if the wallet is skilled.
Ignoring strategy drift
Wallets change. Some traders get larger and less nimble. Others move from disciplined setups into looser speculation.
Over-allocating to one signal
Even a strong ranking shouldn't push you into concentration you can't handle.
Confusing recent success with durable reliability
A hot stretch can lift any profile. What matters is whether the behavior still looks sound when the easy trades disappear.
Survivorship bias subtly distorts wallet analysis.
You usually study wallets that are still visible, active, and interesting. The failed wallets drop out of attention. That creates a cleaner-looking field than reality deserves. A ranking helps reduce noise, but it doesn't erase the fact that you're often evaluating survivors.
A mature process usually looks like this:
Good traders use rankings to ask better questions. Weak traders use rankings to avoid asking any.
Yes.
A wallet can be highly reliable because its behavior is consistent, controlled, and understandable, even if it doesn't produce the most explosive returns. Another wallet might make more money over a short stretch while taking much messier risk. Reliability and raw upside aren't the same thing.
No.
More trades can give you more data to inspect, but frequency alone doesn't make a wallet dependable. A trader who overtrades can look active while producing noisy, hard-to-copy signals. Quality beats quantity.
No.
Treat the ranking as a starting filter. You still need to check whether the wallet's hold time, position sizing, and drawdown profile fit your own process. A slightly lower-ranked wallet that matches your style is often the better copy target.
Neither should stand alone.
Win rate tells you how often the trader is right. Drawdown tells you how painful it gets when the trader is wrong or out of sync. For copy traders, drawdown often matters more than they first expect because it affects whether they can stay in the strategy long enough to benefit from the edge.
Regularly.
The exact cadence depends on your trading style, but the core idea is simple. Reliability is not a permanent label. A wallet can drift, slow down, speed up, or change how it sizes risk. Re-checking keeps you from following an outdated version of the signal.
Partly.
The inputs can be systematic, but the final score always reflects choices about weighting and methodology. If one ranking favors low drawdown and another favors aggressive upside, both may be internally consistent while producing different wallet orders.
Use a three-part filter:
If all three line up, the wallet is worth deeper attention. If one breaks, move on.
If you want to turn raw wallet activity into something you can trade from, Wallet Finder.ai gives you a way to review wallet histories, filter by behavior, track trades across major chains, and monitor signals in real time so you can judge reliability before you commit capital.

A premier DeFi analytics platform empowering traders to discover and analyze profitable blockchain wallets, trades and tokens.

