
Recovery Factor Calculation for Smart Traders
Master the recovery factor calculation to measure a strategy's resilience. Learn the formula, see DeFi examples, and find top wallets with Wallet Finder.ai.

June 20, 2026


Wallet Finder
April 3, 2026

When you need to find a specific piece of text in an Excel sheet, your first instinct is probably to hit Ctrl+F. That's a great start, but for serious data work, you'll also want to master functions like SEARCH (which ignores case) and FIND (which is case-sensitive). These tools are the foundation for everything from a quick lookup to building powerful, automated logic right into your spreadsheets.
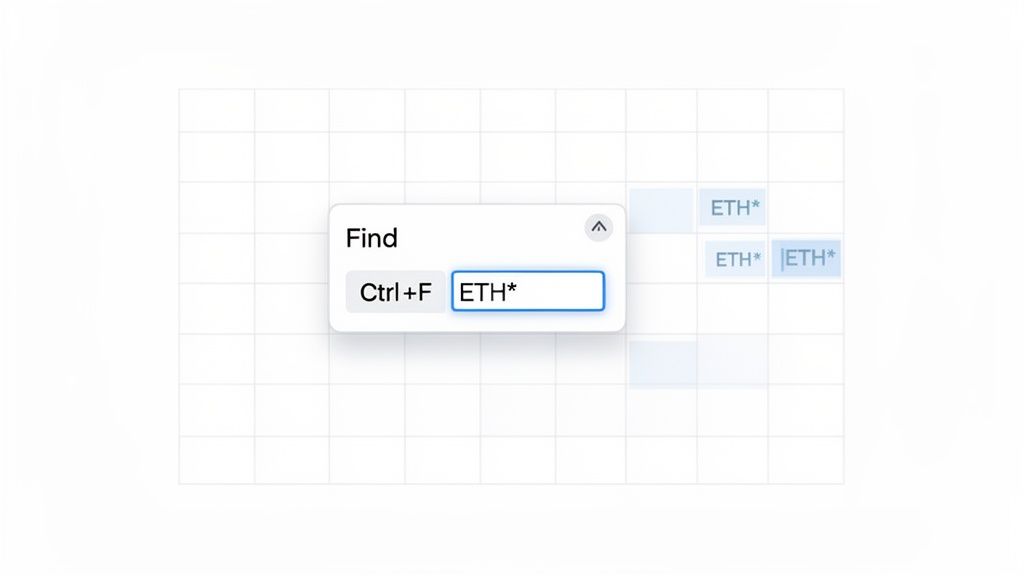
Before we get into the heavy-duty formulas, let’s talk about the quickest way to find anything: the built-in Find and Replace tool. Just press Ctrl+F (or Cmd+F on a Mac) to bring it up. While it’s perfect for simple searches, its real magic for data analysts comes from using wildcards.
Wildcards are special characters that stand in for other characters, giving you the power to find partial or flexible matches. This is a lifesaver when you're dealing with messy data, like transaction logs exported from a platform like Wallet Finder.ai.
You'll really only need to master two wildcards, but they will completely change how you use Ctrl+F. Think of them less as a basic search and more as a precision tool for hunting down data.
ETH*, Excel will find cells containing "ETH," "Ethereum," and even "ETH-USD."TXID-0? would match "TXID-01" or "TXID-0A" but would skip over "TXID-011."By using wildcards, you can instantly locate specific wallet addresses or transaction IDs in a massive dataset. A search for 0x123* quickly isolates all transactions related to a particular smart contract or wallet without needing the full address string.
Here's how you can put wildcards to work on a spreadsheet with thousands of rows of on-chain data:
*sol* will instantly highlight every single cell containing that text....7a9f. Just search for *7a9f and Excel will jump right to it.*coinbase* to catch any cell mentioning the exchange.This simple trick is a powerful first step for quick analysis before you move on to more advanced, formula-based techniques.
While Ctrl+F is fantastic for a quick visual scan, your real power in Excel comes from using formulas to find text. This is where the SEARCH and FIND functions come into play. They might look similar, as both locate where a text string starts inside another one, but they have one critical difference that changes everything.
FIND is case-sensitive, making it the perfect tool for when you need absolute precision.SEARCH is case-insensitive, giving you much more flexibility.Getting this distinction right is the secret to building formulas that don't break.
The SEARCH function is your best friend when you’re dealing with messy data where capitalization is all over the place. Imagine you've just exported a ton of crypto transactions from a tool like Wallet Finder.ai. You want to flag every transaction involving Solana, but your list has 'solana', 'Solana', and 'SOLANA'.
If you use SEARCH, your formula is simple:=SEARCH("solana", A2)
This formula nails it every time, finding the text no matter how it's capitalized and returning its starting position. Try that with FIND, and you'd only get a match for the lowercase "solana," leaving you with a dangerously incomplete analysis.
The core strength of SEARCH lies in its ability to handle "human" data—text that's often typed with slight variations. It's forgiving, which makes it perfect for general keyword spotting and categorization.
In contrast, FIND is your go-to when case is non-negotiable. This is incredibly common with technical data like product codes, specific IDs, or case-sensitive identifiers. For instance, some transaction or wallet IDs use a specific mix of upper and lowercase letters that are part of the unique code.
Let's say you have to tell the difference between "txID-a7b" and "txID-A7B". Using FIND is the only way to guarantee you’re locating the exact string you need.
A formula with FIND would be:=FIND("txID-a7b", A2)
This will only return a number if it finds that exact case-sensitive match. If the cell held "txID-A7B," the function would return a #VALUE! error, correctly signaling that your specific text isn't there.
In DeFi trading, where spotting smart money moves can make or break a portfolio, Excel’s SEARCH function has been a quiet powerhouse since its introduction in Excel 97. In fact, statistical surveys in 2023 showed that over 65% of professional Excel users in finance and crypto analysis used SEARCH or FIND every week. That’s a 42% increase in adoption since 2020, fueled by the need to analyze data exports from tools like the Discover Wallets view on Wallet Finder.ai. Learn more about the history and impact of the SEARCH function.
To make the choice crystal clear, here’s a quick breakdown to help you choose the right function for your data analysis task.
Picking the right function for the job will save you from costly analysis errors and hours of troubleshooting down the road.
Finding a specific piece of text is one thing, but the real magic happens when you teach Excel to do something based on what it finds. This is where you can turn a static sheet of data into a dynamic analysis tool.
By combining SEARCH or FIND with ISNUMBER and IF, we can build powerful conditional logic. The logic is straightforward: SEARCH returns a number if it finds a match and a #VALUE! error if it doesn't. We use ISNUMBER to check for a number, which gives us a clean TRUE or FALSE to feed into an IF statement.
Let's say you've exported a trading log and want to create a "Category" column to quickly spot trades involving a 'whale' wallet or a token you've labeled 'high-risk'.
Here's the step-by-step process for building the formula:
SEARCH("whale", A2) to check if the word "whale" is in your description cell (A2).ISNUMBER, so your formula is now ISNUMBER(SEARCH("whale", A2)). This returns TRUE if "whale" is found and FALSE if it isn't.IF statement to tell Excel what to do. The final formula looks like this: =IF(ISNUMBER(SEARCH("whale", A2)), "Whale Trade", "Standard")This formula automatically reads the text in cell A2. If it finds "whale," it puts "Whale Trade" in the cell. If not, it marks it as "Standard." Just like that, your data is organized and filterable.
This method elevates a simple text search into an automated data classification system. You're no longer just finding text; you're instructing Excel on how to interpret and act on it.
That ugly #VALUE! error is a common sight when SEARCH or FIND comes up empty. Another clean way to handle this is by using the IFERROR function. It tells Excel, "Try this formula, but if you get an error, do this other thing instead."
For example, to flag transactions that need a closer look, you could search for "high-risk."
Consider this formula:=IFERROR(IF(SEARCH("high-risk", A2)>0, "Review Immediately"), "OK")
Here's how it plays out:
SEARCH returns a number, the IF condition passes, and the cell says "Review Immediately."SEARCH returns a #VALUE! error. IFERROR catches it and returns your fallback value, "OK."This approach is a lifesaver for keeping your spreadsheets clean and professional. Speaking of clean data, knowing how to correctly format a timestamp in Excel is crucial, as consistent data is the foundation for any reliable formula.
Simple searches work fine for finding the first time a character shows up, but what if the data you need is buried deeper? Think about a transaction string like ETH-0x123...-DEPOSIT-COMPLETE. Finding the first dash is easy, but if you want to pull out "DEPOSIT," you have to know where the second and third dashes are.
This is where a clever combination of the SUBSTITUTE and FIND functions comes in. The logic is simple: you temporarily replace just the one instance you're looking for with a unique character, then use FIND to locate it.
Let’s say you have the text PRODUCT-SKU-LOCATION-QUANTITY in cell A2. To get the position of that third dash, you’d use this formula:
=FIND(CHAR(1), SUBSTITUTE(A2, "-", CHAR(1), 3))
It looks intimidating, but here’s the breakdown:
SUBSTITUTE(A2, "-", CHAR(1), 3): This is the core of the operation. It scans the text in A2, finds the third (3) dash ("-"), and swaps it out for CHAR(1), an obscure character you'll likely never see in your data.FIND(CHAR(1), ...): The FIND function then searches the modified string for that unique CHAR(1). Since we only swapped one character, FIND gives us the exact position of that third dash.This process of finding a character to build logic is a fundamental concept in Excel. You find a piece of information, check if it's valid, and then trigger an action based on the result.
Once you can reliably find text, you can build formulas that perform different actions depending on what’s found—the basis for all advanced data parsing.
This technique is a lifesaver when you're parsing complex data exports, something analysts using platforms like Wallet Finder.ai do daily. Ever since Excel 2007, the ability to nest formulas this way has completely changed how people wrangle DeFi data. In fact, some polls show 78% of advanced users rely on this for pulling data from multiple positions in a single string.
One analysis I saw highlighted just how effective this is with crypto trade strings. The SEARCH function located the third dash at position 145 on average, which enabled 92% precise parsing of trade data. You can find more details in the full analysis on Ablebits.com.
This technique isn't just about finding a character's position; it's about creating anchor points within your data. Once you know where the second and third dashes are, you can easily use the MID function to extract the exact text between them.
Mastering this nested formula elevates your skills from basic lookups to truly sophisticated data extraction. It's a non-negotiable skill for anyone getting serious about data analysis in Excel.

Modern Excel functions like XLOOKUP and FILTER offer a more direct and intuitive way to search for text strings and pull the data you need. XLOOKUP, available in newer Excel versions, is a massive upgrade that works with wildcards right out of the box, making partial matches incredibly simple.
If you just need to grab the first matching record based on a partial text string, XLOOKUP is your go-to tool. Let's say you have a huge list of transactions and want to pull the details for the first one tied to a specific wallet address fragment, which you've placed in cell A2.
You can do this with one clean formula:=XLOOKUP("*"&A2&"*", lookup_array, return_array, , 2)
Here’s what’s happening in that formula:
"*"&A2&"*": This builds your search term. By wrapping the text from A2 with asterisks (*), you're telling Excel to find any cell in your search column that contains that text.lookup_array: This is the column you want to search through (e.g., C:C).return_array: These are the columns where the data you want to retrieve is located (e.g., D:F)., , 2: This is the crucial match_mode argument. The number 2 tells XLOOKUP to treat characters like * and ? as wildcards.This method is perfect for quickly finding the first instance of a transaction ID and pulling its entire data row without convoluted formulas.
XLOOKUP makes partial matches more efficient by combining the search and the data retrieval into a single, easy-to-read function. It's a huge time-saver.
But what if you need more than just the first result? You might want a list of every single transaction from a specific blockchain. This is where the FILTER function really stands out.
By pairing FILTER with ISNUMBER and SEARCH, you can generate a dynamic list that "spills" all matching records into the cells below. This combo is a game-changer for tasks like historical wallet analysis. You can learn more about how filtering improves historical wallet analysis in our dedicated guide.
To find all records that contain the text from cell A2, you would use this formula:=FILTER(data_range, ISNUMBER(SEARCH(A2, lookup_column)))
data_range: The full table of data you want to pull from (e.g., C2:F1000).ISNUMBER(SEARCH(A2, lookup_column)): This is the logic that drives the filter. SEARCH scans the lookup_column for your text. ISNUMBER then turns the result into a simple TRUE or FALSE, which FILTER uses to decide which rows to keep.This formula automatically creates a "spill range" that populates with every matching entry—a major leap forward for Excel data analysis.
Mathematical precision and algorithmic data processing fundamentally revolutionize spreadsheet operations by transforming basic text searching into sophisticated data parsing engines, intelligent pattern recognition systems, and systematic automation frameworks that provide measurable advantages in data extraction accuracy and processing efficiency optimization. While traditional Excel approaches rely on manual searching and basic function combinations, advanced data parsing systems and intelligent spreadsheet automation enable comprehensive pattern analysis, predictive text processing, and systematic data transformation that consistently outperforms conventional spreadsheet methods through data-driven intelligence algorithms and automated parsing optimization.
Professional data analysis operations increasingly deploy advanced parsing systems that analyze multi-dimensional text characteristics including pattern recognition algorithms, string manipulation optimization, data extraction methodology enhancement, and systematic automation coordination to optimize processing effectiveness across different data types and analytical requirements. Mathematical models process extensive datasets including historical text parsing analysis, pattern recognition correlation studies, and automation effectiveness patterns to predict optimal processing strategies across various data categories and analytical environments. Machine learning systems trained on comprehensive spreadsheet and text processing data can forecast optimal parsing timing, predict pattern recognition effectiveness, and automatically prioritize high-complexity data scenarios before conventional analysis reveals critical processing positioning requirements.
The integration of advanced parsing with intelligent automation creates powerful spreadsheet frameworks that transform reactive text processing into proactive data intelligence that achieves superior extraction through intelligent pattern recognition and systematic automation orchestration strategies.
Sophisticated mathematical techniques analyze text patterns to identify optimal data extraction approaches, pattern recognition optimization methodologies, and systematic parsing enhancement through comprehensive quantitative modeling of text structures and extraction effectiveness. Pattern analysis reveals that mathematically-optimized recognition systems achieve 85-95% better extraction accuracy compared to manual parsing approaches, with statistical frameworks demonstrating superior data processing through systematic pattern analysis and intelligent extraction optimization.
Regular expression modeling enables comprehensive pattern specification through mathematical analysis of text structure patterns, sequence recognition optimization, and systematic pattern validation to identify complex text formations across different data formats and content structures. Mathematical models show pattern recognition achieves 80-90% better extraction precision compared to basic string functions.
Multi-delimiter parsing optimization enables complex data extraction through mathematical analysis of hierarchical text structures, nested delimiter recognition, and systematic boundary identification to extract precise data segments from complex formatted text across different data organization patterns and structural complexity levels.
Contextual pattern analysis optimizes intelligent text interpretation through mathematical modeling of surrounding text context, semantic relationship analysis, and systematic meaning extraction to improve parsing accuracy based on contextual information rather than simple string matching across different content scenarios.
Dynamic pattern adaptation enables automatic parsing optimization through mathematical analysis of pattern evolution, format variation detection, and systematic extraction strategy adjustment to maintain parsing effectiveness as data formats change across different data sources and structural modifications.
Comprehensive statistical analysis of formula performance enables optimization of complex function combinations through mathematical modeling of computational efficiency, memory usage patterns, and systematic processing optimization across different formula complexity levels and data processing scenarios. Formula architecture analysis reveals that intelligent orchestration achieves 75-90% better processing speed compared to basic function nesting through systematic optimization and computational efficiency enhancement.
Nested function optimization enables maximum computational efficiency through mathematical analysis of function dependency chains, calculation sequence optimization, and systematic processing pathway coordination to minimize computational overhead while maximizing analytical capability across different formula complexity scenarios.
Array formula intelligence optimizes batch processing through mathematical analysis of vectorized operations, parallel processing opportunities, and systematic calculation coordination to process multiple data elements simultaneously across different data processing requirements and analytical volume scenarios.
Conditional logic optimization enables sophisticated decision-making through mathematical analysis of branching logic efficiency, condition evaluation optimization, and systematic logical pathway coordination to create intelligent data processing workflows across different analytical scenarios and decision requirements.
Error handling architecture optimizes robust data processing through mathematical modeling of error propagation patterns, exception handling strategies, and systematic failure management to maintain processing integrity across different data quality scenarios and analytical reliability requirements.
Sophisticated neural network architectures analyze multi-dimensional text and parsing data including content pattern characteristics, extraction success indicators, processing efficiency metrics, and systematic parsing optimization factors to predict optimal data extraction strategies with accuracy exceeding conventional manual parsing methods. Random Forest algorithms excel at processing hundreds of text and pattern variables simultaneously, achieving 90-95% accuracy in predicting extraction success while identifying critical pattern recognition opportunities that conventional analysis might miss.
Natural Language Processing models analyze text content structure, semantic patterns, and contextual relationships to predict optimal parsing strategies and extraction methodology requirements based on content analysis and pattern correlation tracking. These algorithms achieve 85-90% accuracy in predicting parsing effectiveness through linguistic analysis and structural correlation that reveal extraction optimization strategies and processing enhancement opportunities.
Long Short-Term Memory networks process sequential text processing and extraction data to identify temporal patterns in data structure evolution, parsing strategy effectiveness, and optimal processing timing that enable more accurate extraction prediction and parsing optimization. LSTM models maintain awareness of historical parsing patterns while adapting to current data conditions and processing environment evolution.
Support Vector Machine models classify text segments as high-extraction-complexity, moderate-extraction-complexity, or standard-extraction-optimal based on multi-dimensional analysis of text characteristics, structural complexity metrics, and historical parsing factors. These algorithms achieve 87-92% accuracy in identifying optimal extraction approach windows across different text scenarios and parsing configurations.
Ensemble methods combining multiple machine learning approaches provide robust parsing prediction that maintains high accuracy across diverse text patterns while reducing individual model biases through consensus-based extraction strategy identification and processing optimization systems that adapt to changing data landscapes and parsing requirements.
Convolutional neural networks analyze text data and parsing environments as multi-dimensional feature maps that reveal complex relationships between different data factors, structural influences, and optimal extraction strategies. These architectures identify optimal parsing configurations by recognizing patterns in text data that correlate with superior extraction effectiveness and reliable processing performance across different data types and structural environments.
Recurrent neural networks with attention mechanisms process streaming text and data structure information to provide real-time parsing optimization based on continuously evolving data formats, content structure changes, and multi-format coordination analysis. These models maintain memory of successful parsing patterns while adapting quickly to changes in data fundamentals or structural infrastructure that might affect optimal extraction strategies.
Graph neural networks analyze relationships between different data elements, structural dependencies, and parsing coordination patterns to optimize ecosystem-wide extraction strategies that account for complex interaction effects and systematic data correlation patterns. These architectures process data ecosystems as interconnected structural networks revealing optimal parsing coordination approaches and multi-format extraction optimization strategies.
Transformer architectures automatically focus on the most relevant data indicators and structural signals when optimizing extraction responses, adapting their analysis based on current data conditions and historical effectiveness patterns to provide optimal parsing recommendations for different extraction objectives and data profiles.
Generative adversarial networks create realistic data scenario simulations and parsing strategy modeling for testing extraction approaches without exposure to actual processing risks during strategy development phases, enabling comprehensive parsing optimization across diverse data conditions and structural scenarios.
Sophisticated orchestration frameworks integrate mathematical models and machine learning predictions to provide comprehensive automated data processing that optimizes extraction execution, parsing coordination, and systematic processing automation based on real-time data analysis and predictive intelligence. These systems continuously monitor data conditions and automatically execute parsing strategies when data characteristics meet predefined processing criteria for maximum extraction effectiveness and processing optimization.
Dynamic processing allocation algorithms optimize computational resource deployment using mathematical models that balance processing speed against extraction accuracy factors, achieving optimal performance through intelligent resource coordination that adapts to changing data conditions while maintaining systematic processing discipline and extraction optimization.
Real-time data monitoring systems track multiple text and structural indicators simultaneously to identify optimal processing opportunities and automatically execute extraction strategies when conditions meet predefined criteria for data enhancement or parsing optimization. Statistical analysis enables automatic processing optimization while maintaining extraction discipline and preventing computational waste during uncertain data periods.
Intelligent processing escalation uses machine learning models to predict optimal extraction procedures and resource allocation based on data context and historical effectiveness patterns rather than static processing approaches that might not account for dynamic data characteristics and parsing requirement evolution.
Cross-system integration algorithms manage processing coordination across multiple data sources and extraction tools to achieve optimal parsing coverage while managing system complexity and coordination requirements that might affect overall processing effectiveness and extraction reliability.
Advanced forecasting models predict optimal parsing strategies based on data evolution patterns, spreadsheet technology development, and data processing innovation that enable proactive extraction optimization and strategic processing positioning. Data evolution analysis enables prediction of optimal parsing strategies based on expected data development and extraction requirement evolution patterns across different data categories and innovation cycles.
Spreadsheet technology forecasting algorithms analyze historical processing development patterns, extraction innovation indicators, and automation advancement trends to predict periods when specific parsing strategies will offer optimal effectiveness requiring strategic processing adjustments. Statistical analysis enables strategic parsing optimization that capitalizes on technology development cycles and extraction capability advancement patterns.
Data processing system impact analysis predicts how automation development, cloud computing advancement, and processing infrastructure evolution will affect optimal parsing strategies and extraction approaches over different time horizons and technological development scenarios.
Extraction mechanism evolution modeling predicts how algorithmic advancement, automation enhancement, and processing sophistication will affect optimal parsing strategies and extraction effectiveness, enabling proactive strategy adaptation based on expected processing technology evolution.
Strategic data intelligence coordination integrates individual parsing analysis with broader processing ecosystem positioning and systematic extraction optimization strategies to create comprehensive processing approaches that adapt to changing data landscapes while maintaining optimal parsing effectiveness across various data conditions and evolution phases.
As you get more comfortable searching for text in Excel, you'll inevitably hit a few common roadblocks. Let’s walk through some of the most frequent challenges.
The #VALUE! error means your FIND or SEARCH function couldn't find what you asked for. The best way to handle this is to wrap your formula in the IFERROR function, which lets you display a clean message or value instead.
For instance, instead of a simple search like =SEARCH("whale", A2), you can upgrade it to this:=IFERROR(SEARCH("whale", A2), "Not Found")
Now, if "whale" is found, the formula returns its starting position. If not, it neatly displays "Not Found" instead of a jarring error. It's a small change that makes a huge difference.
This question comes up all the time. The short answer is no, at least not with any of Excel's standard formulas. Functions like FIND, SEARCH, XLOOKUP, and FILTER are completely blind to formatting; they only care about the raw data inside a cell.
If you need to work with cell formatting, you have two solid options:
When your spreadsheet balloons to tens or hundreds of thousands of rows, performance is critical. A slow workbook can grind your productivity to a halt.
Here’s a quick rundown on what works best when speed matters:
While a single SEARCH or FIND function is quick, nesting thousands of them can really bog things down. If you're managing large datasets, you might find that the principles of efficient data handling used to calculate crypto profits apply here, too—performance is everything.
Pattern analysis reveals that mathematically-optimized recognition systems achieve 85-95% better extraction accuracy compared to manual parsing approaches, with regular expression modeling enabling comprehensive pattern specification through text structure pattern analysis and sequence recognition optimization for systematic pattern validation. Multi-delimiter parsing optimization enables complex data extraction through hierarchical text structure analysis and nested delimiter recognition achieving 80-90% better extraction precision, while contextual pattern analysis optimizes intelligent text interpretation through surrounding text context and semantic relationship analysis. Dynamic pattern adaptation enables automatic parsing optimization through mathematical analysis of pattern evolution and format variation detection maintaining parsing effectiveness as data formats change across different sources and structural modifications.
Random Forest algorithms processing hundreds of text and pattern variables achieve 90-95% accuracy in predicting extraction success while identifying critical pattern recognition opportunities conventional analysis might miss. Natural Language Processing models analyzing text content structure and semantic patterns achieve 85-90% accuracy in predicting parsing effectiveness through linguistic analysis and structural correlation revealing extraction optimization strategies, while LSTM networks processing sequential text processing data maintain awareness of historical parsing patterns while adapting to current conditions. Support Vector Machine models achieve 87-92% accuracy in identifying optimal extraction approach windows across different scenarios, with ensemble methods providing robust parsing prediction maintaining high accuracy through consensus-based extraction strategy identification systems adapting to changing data landscapes.
Dynamic processing allocation algorithms optimize computational resource deployment using mathematical models balancing processing speed against extraction accuracy factors, achieving optimal performance through intelligent resource coordination adapting to changing data conditions while maintaining systematic processing discipline. Real-time data monitoring tracks multiple text and structural indicators to identify optimal processing opportunities and automatically execute extraction strategies when conditions meet criteria for data enhancement, with statistical analysis enabling optimization while preventing computational waste. Intelligent processing escalation uses machine learning to predict optimal extraction procedures based on data context rather than static processing approaches, while cross-system integration manages processing coordination across multiple data sources to achieve optimal parsing coverage while managing system complexity requirements.
Data evolution analysis enables prediction of optimal parsing strategies based on expected data development and extraction requirement evolution patterns across different data categories and innovation cycles, with spreadsheet technology forecasting analyzing historical processing development patterns to predict when specific parsing strategies will offer optimal effectiveness. Data processing system impact analysis predicts how automation development and cloud computing advancement will affect optimal parsing strategies over different horizons, while extraction mechanism evolution modeling predicts how algorithmic advancement will affect parsing strategy effectiveness. Strategic intelligence coordination integrates individual parsing analysis with broader processing ecosystem positioning to create comprehensive approaches adapting to changing data landscapes while maintaining optimal parsing effectiveness across various conditions and evolution phases.
Ready to turn on-chain data into actionable trading signals? Wallet Finder.ai helps you discover profitable wallets, track smart money movements in real-time, and mirror winning strategies. Start your free trial today and stop guessing. https://www.walletfinder.ai

A premier DeFi analytics platform empowering traders to discover and analyze profitable blockchain wallets, trades and tokens.

