
Recovery Factor Calculation for Smart Traders
Master the recovery factor calculation to measure a strategy's resilience. Learn the formula, see DeFi examples, and find top wallets with Wallet Finder.ai.

June 20, 2026


Wallet Finder
June 16, 2026
You spot the move after the chart already broke out. A wallet rotated into a small-cap token, volume followed, social accounts woke up, and by the time your dashboard refreshed the clean entry was gone.
That gap between event and action is where real time data processing matters. In trading, especially in DeFi, the difference between seeing a swap now and seeing it later changes whether you capture the move or end up studying it after the fact.
Most traders don't need a textbook definition. They need a system that catches on-chain events as they happen, filters noise, enriches raw transactions with context, and pushes a signal while the trade still matters. That's what real time pipelines do. They replace retrospective analysis with live decision support.
In older data stacks, teams collected records, stored them, and analyzed them later. That approach still works for compliance reporting, month-end finance, and long-range trend analysis. It fails when the value of the data decays within seconds.
Trading is the clearest example. A token buy from a high-conviction wallet is useful when you see it immediately. If the same event reaches you after the crowd piles in, the data may still be accurate, but it's no longer actionable.
According to IBM's summary of IDC enterprise survey findings and related industry analysis, 63% of real-time data use cases must process information within minutes to be considered useful. That number is important, but the bigger lesson for traders is the split inside the category. Some workflows can tolerate seconds or minutes. High-stakes workflows such as fraud detection, critical alerts, and trading signals need sub-second response to preserve their edge.
That distinction matters in DeFi because on-chain information is public. If many participants can see the same transaction, the winner is often the one whose pipeline detects, qualifies, and routes the signal first.
Practical rule: In markets, “real time” doesn't mean “fast sounding.” It means data arrives early enough to change a trade decision.
The shift has been from batch snapshots to continuous event streams. Instead of waiting for a scheduled job, the system treats every new transaction, wallet movement, transfer, or contract interaction as an event that can trigger immediate processing.
For crypto desks and copy traders, that changes daily operations:
The competitive edge comes from shortening the path from chain event to decision. That sounds simple. The engineering behind it isn't.
Real time data processing and batch processing solve different problems. Confusing them leads to bad architecture and worse trading systems.
A simple analogy helps. Batch processing is like developing a roll of film. You capture moments, wait, and review them later as a set. Real time processing is like a live video feed. You see events as they unfold and can act while the scene is still changing.
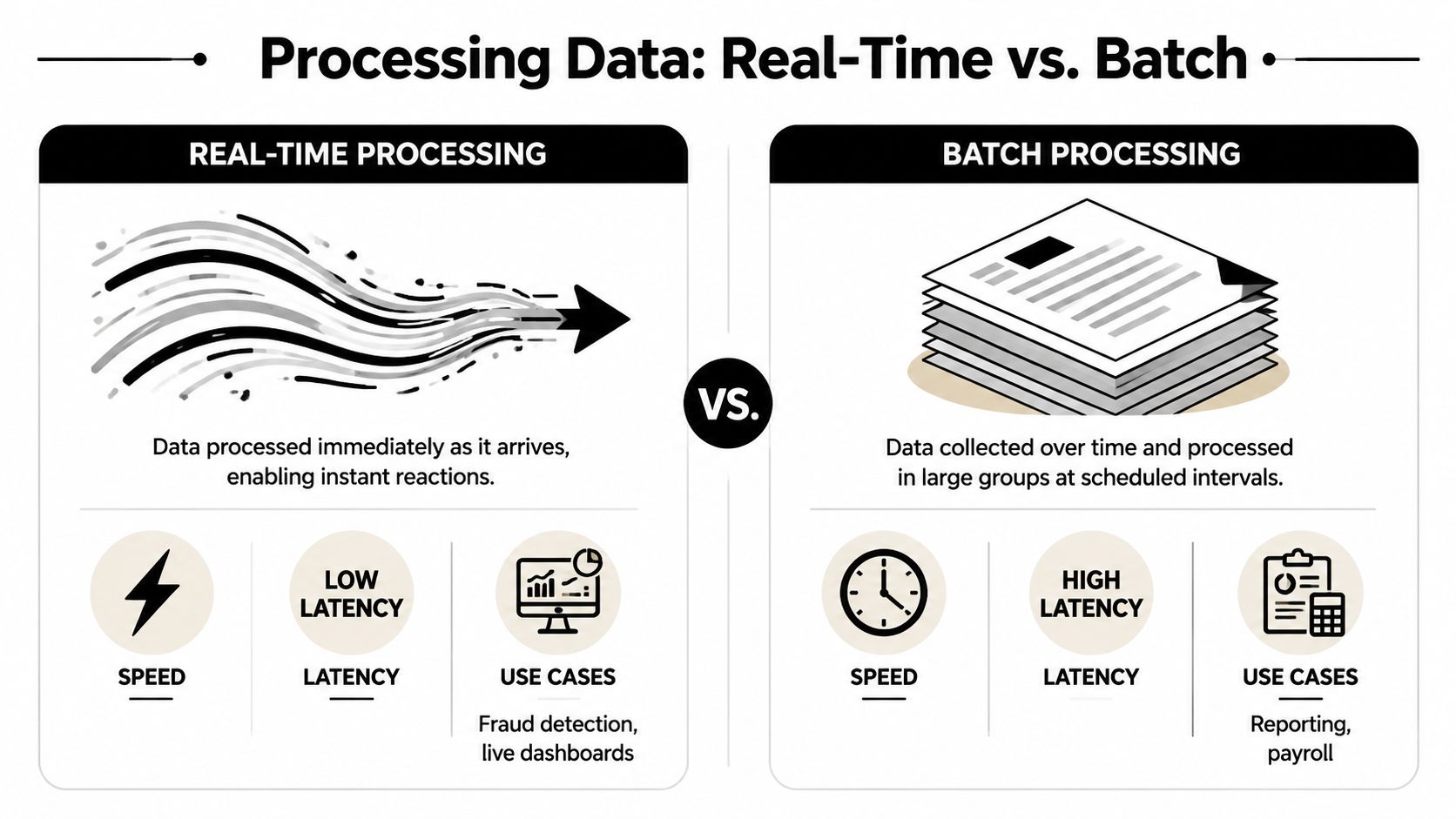
In practice, the line isn't philosophical. It's operational. CrateDB's definition of real-time data processing describes it as end-to-end latency in the milliseconds to seconds range, with continuous ingestion, incremental computation as events arrive, and immediate availability for downstream actions such as dashboards, alerts, or automated workflows.
Batch is still useful when you care more about completeness than immediacy. End-of-day PnL, historical research, tax exports, and portfolio reviews fit well there.
Streaming becomes the right model when delay changes the value of the outcome. In DeFi, that includes wallet tracking, risk alerts, liquidation monitoring, bridge flow changes, and rapid rotation into new pairs.
Here's the clean comparison.
| Characteristic | Batch Processing | Real-Time Processing |
|---|---|---|
| Data arrival | Collected over a period, then processed | Processed continuously as events arrive |
| Latency | Usually later, often minutes or longer | Milliseconds to seconds |
| Analysis model | Retrospective | In-motion, incremental |
| Best for | Reporting, audits, historical analysis | Alerts, monitoring, live trading signals |
| User experience | Static or delayed views | Live dashboards and immediate notifications |
| Trading value | Useful for review | Useful for action |
A short explainer helps frame the distinction visually.
A lot of teams say they need real time when they really need near-real-time. That matters because every reduction in latency usually increases system complexity, infrastructure cost, and operational burden.
Use this filter before you build:
A delayed signal isn't just slower. In trading, it can become a different signal entirely.
A good real time pipeline isn't one tool. It's a chain of responsibilities. For trading systems, I think about it in four stages: Ingest, Process, Store, Serve.
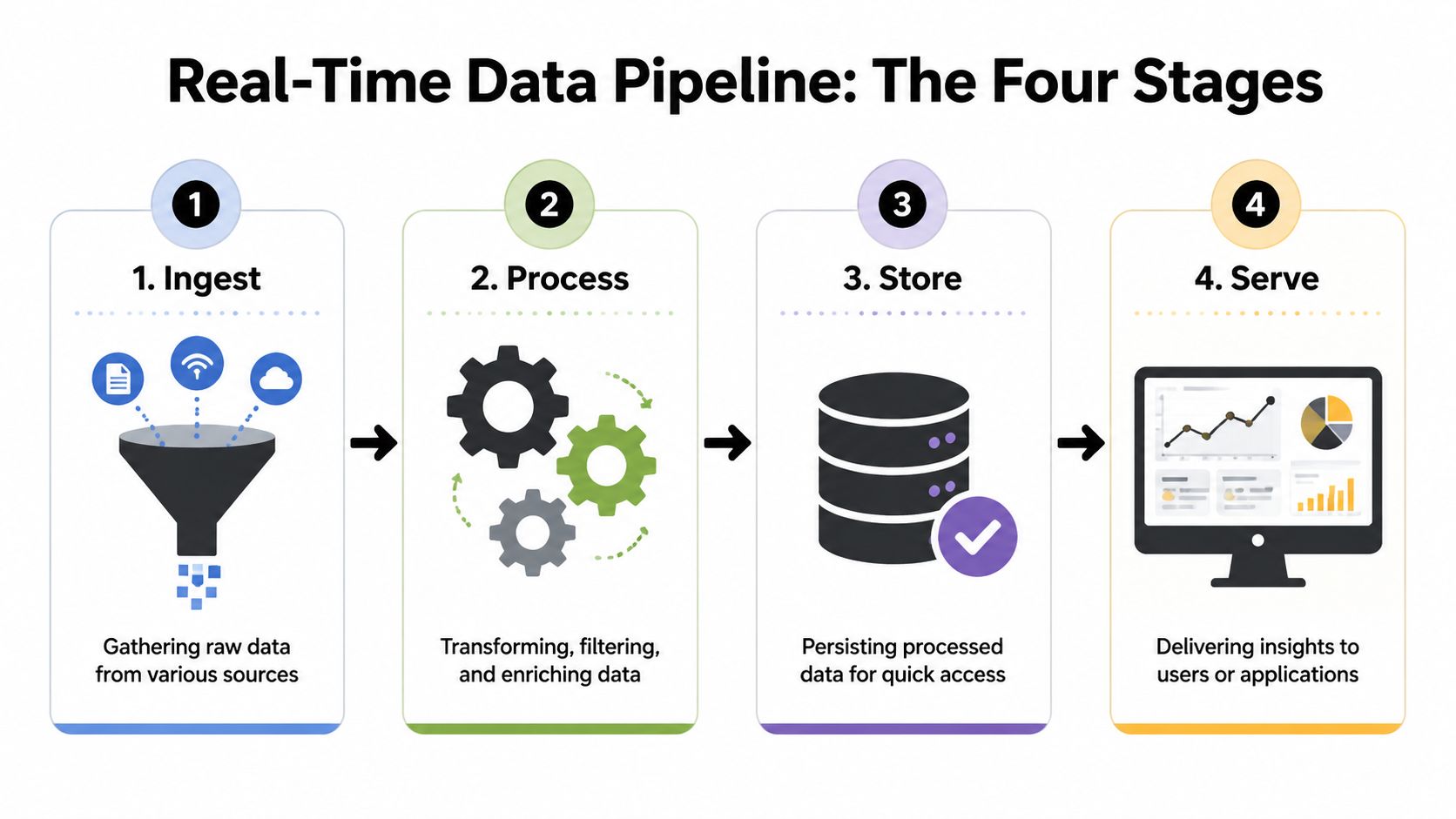
If any one of those stages is weak, the whole pipeline suffers. You can't compensate for bad ingestion with a fancy dashboard, and you can't fix poor serving latency by over-optimizing storage.
This is the front door. The system receives raw events from blockchains, exchange feeds, wallet activity streams, mempool watchers, or application logs.
In a DeFi workflow, an ingest layer might capture:
The key requirement is continuity. The ingest layer can't assume quiet periods or tidy arrivals. Chains get noisy, bursty, and irregular.
This stage is the brain of the system. Fivetran's overview of high-performance real-time pipelines describes an event-driven architecture where sources emit discrete events into a streaming backbone, a stream processor performs filtering, enrichment, joins, or aggregations, and results are pushed to applications. It also notes that pre-filtering and materializing commonly used fields can materially lower latency and CPU cost.
That advice maps directly to trading systems. Raw blockchain events are too noisy to ship directly to users. The processor needs to answer questions such as:
From raw chain data, useful signal emerges.
Real time systems still store data. They just store it in a way that supports fast reads on fresh events.
For DeFi analytics, I usually separate storage responsibilities:
| Storage need | What it holds | Why it matters |
|---|---|---|
| Hot store | Recent enriched events | Fast alerting and live dashboards |
| Analytical store | Broader history | Pattern analysis and wallet scoring |
| Durable archive | Raw source events | Replay, audits, and backfills |
A common mistake is trying to use one storage pattern for all three. That usually produces either slow alerts or painful operations.
Serving is the delivery layer. It exposes the processed signal to humans and systems through APIs, dashboards, push notifications, or bots.
In the smart-money workflow, this final step is where a qualified wallet buy becomes a message in Telegram, a row in a watchlist, or a trigger for a risk model.
Fast ingest without fast serving still feels slow to the trader.
The best serving layers do two things well. They return recent context instantly, and they package the event in a format a user can act on without opening six more tabs.
The stack becomes easier to understand when you group tools by function instead of memorizing product names.
One broad trend is already clear. Over 70% of new enterprise data architectures now include an event-streaming layer, according to the portable industry analysis and Striim reports cited in the verified material. That isn't hype. It reflects a practical shift toward systems that can react immediately instead of waiting for scheduled data movement.
This layer transports events reliably.
For crypto teams exposing market data to products, a strong API layer matters just as much as the message bus. A practical piece like this guide to a crypto prices API illustrates its integration into the larger design, showing the serving side of the stack, where fresh data becomes something applications can query.
This layer transforms events into signals.
| Tool type | Role in the pipeline | Typical use |
|---|---|---|
| Stream processor | Stateful event computation | Filtering, joins, windowing |
| Streaming SQL layer | Query-style transformations | Rapid modeling, aggregations |
| Custom services | Strategy-specific logic | Wallet scoring, alert rules |
Common names include Apache Flink for stateful stream processing and Spark Structured Streaming for teams already invested in the Spark ecosystem. For lighter SQL-driven flows, tools like ksqlDB can be effective when the logic is event-centric and the team wants simpler operational ergonomics.
Many trading teams underinvest. They build a decent ingest path and a clever processor, then force users to query a system that wasn't designed for live reads.
A better pattern is:
What works is boring architecture with disciplined interfaces. What doesn't work is piling more query complexity onto the request path and hoping more hardware saves it.
The easiest way to understand real time data processing is to follow a single event.
A tracked wallet buys a token on-chain. That transaction is public immediately, but public doesn't mean useful. Raw swaps don't tell you whether the wallet is worth following, whether the move is meaningful, or whether the token already looks exhausted.
DeFi differs from slower analytics domains because the system isn't watching for a reportable change. It's watching for a potentially tradable one.
The verified industry analysis notes that while many enterprise workloads can tolerate minute-level latency, financial trading and DeFi demand sub-second processing because even a delay of a few seconds can erase the competitive advantage. In copy trading, that's the entire game. If the alert comes after the first expansion leg, the follower is no longer copying the same trade.
A useful smart-money alert needs enrichment. The system has to check context around the event:
Here, a raw on-chain event turns into a ranked signal.
One practical implementation of this workflow is Wallet Finder.ai, which tracks wallet histories, surfaces on-chain trades, and routes alerts when watched wallets buy, swap, or sell. On the user side, the value isn't the raw data feed. It's the combination of tracking, filtering, and delivery in time to act.
Serving matters more than teams expect. Traders won't open a data warehouse to inspect a new swap. They need an actionable alert with enough context to decide quickly.
That usually means:
| Delivery output | What the trader needs to see |
|---|---|
| Push alert | Wallet, token, action, timing |
| Telegram message | The event plus quick context |
| Live dashboard row | Fresh trade with sortable metadata |
| API response | Structured signal for automation |
If your alerts are part of the workflow, configuration matters too. Traders who depend on mobile execution typically want notification paths they can trust, which is why setup details like push notification controls become operationally important.
A smart-money signal isn't valuable because it exists. It's valuable because it reaches the trader early, cleanly, and with enough context to act.
A lot of real time data processing content obsesses over speed. In production, speed is only half the job. The harder problem is staying fast while the system runs continuously, handles failures, and doesn't corrupt the signal unnoticed.
That's especially true in DeFi. A duplicate alert can push a trader into overtrading. A dropped event can hide the most important wallet move of the day. A lagging consumer can make every signal look technically “real time” in architecture diagrams while arriving too late in practice.
Striim's guidance on real-time streaming operations makes a point that practitioners know well: the hard part isn't just speed, but continuous reliability. These applications need to run for years, and administrators need immediate visibility into issues.
That translates into a short operational checklist:
Not every workflow deserves millisecond obsession. Teams waste money when they push every component toward the lowest possible latency without asking whether the business outcome changes.
Use a decision lens like this:
| Question | If yes | If no |
|---|---|---|
| Does delay change execution quality? | Invest in lower latency | Near-real-time may be enough |
| Can users act automatically on the signal? | Keep the path very short | Human review may tolerate more delay |
| Is the signal high-value and scarce? | Prioritize reliability and freshness | Simpler architecture may be better |
The best systems don't chase speed everywhere. They protect the few paths where lateness destroys value.
The direction is straightforward. More on-chain analysis will move from dashboards that explain what happened to systems that react while events are still unfolding.
That shift won't come from one magic tool. It will come from tighter pipelines, cleaner event models, better serving layers, and smarter enrichment at the moment data arrives. The next step is obvious too. Teams will increasingly run predictive models inside streaming workflows so they can score wallet behavior, classify token activity, and prioritize signals before a trader even opens the app.
For most traders and research teams, building that stack from scratch doesn't make economic sense. Running an event pipeline is one challenge. Keeping it reliable during chain congestion, schema drift, and user-facing alert pressure is another.
The practical takeaway is simple. If real time data processing is part of your edge, treat it like a production system, not a side project. The winning setup is the one that catches the right on-chain event, enriches it quickly, and delivers it in a form you can trust.
If you want smart-money alerts without building your own streaming stack, Wallet Finder.ai gives you a practical way to track profitable wallets, review on-chain behavior, and receive timely alerts when watched wallets trade across major ecosystems.

A premier DeFi analytics platform empowering traders to discover and analyze profitable blockchain wallets, trades and tokens.

