
Recovery Factor Calculation for Smart Traders
Master the recovery factor calculation to measure a strategy's resilience. Learn the formula, see DeFi examples, and find top wallets with Wallet Finder.ai.

June 20, 2026


Wallet Finder
June 12, 2026
You're probably sitting on a backtest that looks clean enough to trade. The equity curve rises, the hit rate feels believable, and the logic sounds smart when you say it out loud. Then you deploy it on live markets, and the thing starts bleeding almost immediately.
That's normal in crypto. It's even more common in on-chain strategies, where traders build signals from wallet tags, swap timing, token launches, and social momentum proxies that looked obvious only after the move already happened.
The problem usually isn't bad luck. The problem is that the strategy learned your dataset, not the market. Out of sample validation is the filter that tells you whether you found a tradable edge or just a polished illusion.
A new DeFi analyst usually makes the same mistake first. They find a cluster of wallets that bought early, filter for profitable trades, copy the behavior into a ruleset, and run a historical simulation. The result looks great because the rules were shaped by the same history they're being judged on.
That's not validation. That's rehearsal.
In trading research, this gap between what looked good in development and what survives on unseen data is large enough to kill a strategy. Quantpedia's review of trading-strategy research found that Sharpe ratios for out-of-sample results were, on average, 33% worse and 44% worse at the median than in-sample results in its summary of the literature on in-sample vs out-of-sample analysis of trading strategies.
On-chain research makes the trap worse because the data feels richer than it really is. You can see wallet histories, token flows, position timing, and PnL trails. That creates the illusion that more visibility means more certainty.
It doesn't.
When you mirror wallets, you're often selecting survivors. You're also looking at behavior after the fact, with full knowledge of which wallets ended up looking smart. That introduces hidden hindsight into the entire research process.
Practical rule: If you discovered the strategy by staring at the winners, assume your first test is biased until proven otherwise.
Overfitting in DeFi rarely announces itself. It usually shows up as one of these:
A strategy that only works on the exact sample that created it isn't a strategy. It's a memory of past noise dressed up as process.
Think of in-sample data as an open-book practice exam. You've seen the material, adjusted your notes, and learned where the easy points are. Out-of-sample data is the actual exam. You don't get to rewrite your answers after seeing the questions.
That's the whole idea.
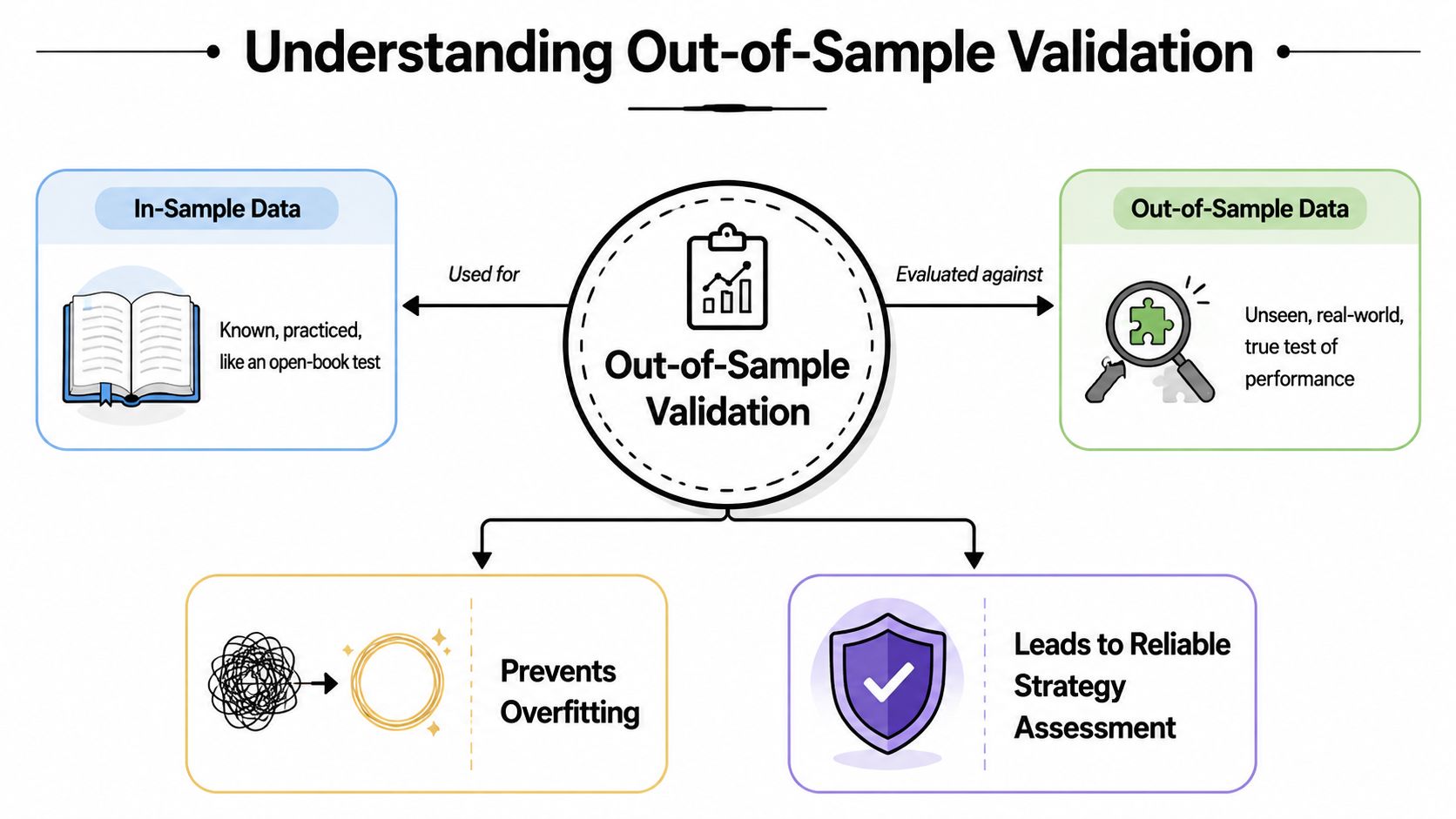
A model or rule set is built on one portion of the data. Then it's evaluated on a separate portion it never saw during development. That second portion is the only place where performance starts to mean something.
Research on validation methodology makes the point clearly: out-of-sample validation is technically stronger because performance must be measured on data the model never saw during training, and that independent evaluation gives a more realistic estimate of generalization before deployment, as described in this review of model evaluation methods.
You only need two core ideas:
For a wallet-mirroring model, in-sample data might include earlier trades from tracked wallets. You use that period to decide what counts as a copyable signal. The out-of-sample segment is the later market period where those rules are frozen and tested without edits.
Out of sample validation doesn't guarantee future profits. It does something more important first. It tells you whether your process can survive first contact with unseen data.
That's why a mediocre-looking out-of-sample result can be more valuable than a gorgeous in-sample backtest. The mediocre result may be honest. The gorgeous one may be fiction.
A strategy that passes on unseen data still isn't proven. A strategy that fails on unseen data is already disqualified.
On-chain analysts often confuse transparency with predictability. Blockchain data is public, but public data still contains noise, lag, execution frictions, and shifting behavior. A profitable wallet can change tactics. A token meta can disappear. A copy-trading rule can stop working once too many people notice it.
Out of sample validation forces discipline. It prevents you from declaring victory just because your rules explain yesterday's winners.
Time-series validation lives or dies on one rule. You must preserve time order. For forecasting and trading systems, the model should be trained on earlier observations and tested on later ones, because random splitting can leak future information into training and artificially inflate accuracy, as explained in this overview of in-sample and out-of-sample forecasting for time-series data.
If you shuffle rows in a crypto dataset, you often hand your model pieces of the future. That's how people end up “predicting” moves that were only visible because the backtest contained a hidden cheat.
This is the simplest method. You divide the series into an earlier training block and a later test block. Build on the first part. Judge on the second.
It's useful when you want a fast first pass on a strategy idea, especially if you're testing a basic ruleset like “mirror wallets only after repeated accumulation in the same token.”
What it gets right is clarity. What it misses is reliability. One split can be misleading if that test period happened to be unusually easy or unusually hostile.
This is the practical workhorse for trading.
You train on an initial period, test on the next period, roll the window forward, retrain, and test again. That mimics how a live research desk operates. You only know the past, you build from it, and then the next block of market data arrives.
Walk-forward validation is especially useful for on-chain systems because wallet behavior evolves. A wallet that was early on Solana memes might later migrate to a different ecosystem or shift from swing trades to launch sniping.
Desk habit: Freeze the rules before each walk-forward segment. If you tweak them after seeing the result, you've turned testing back into training.
Rolling-window validation is similar, but instead of letting the training history keep expanding, you use a moving slice of recent history. That helps when old data may no longer describe the current market.
This can be useful in crypto because older regimes often become irrelevant. A token-launch environment driven by one liquidity structure can behave very differently from a later one. A rolling window lets you emphasize recency.
The drawback is that you may throw away useful longer-term context. Some behaviors repeat across cycles, and a window that's too short can make the strategy unstable.
For most DeFi research, the choice comes down to the question you're asking:
| Method | How It Works | Best For | Main Drawback |
|---|---|---|---|
| Train/Test Split | Train on an earlier block of data and test on a later block once | Fast initial screening of strategy ideas | One test window can give a distorted view |
| Walk-Forward Validation | Repeatedly train on past data, test on the next unseen segment, then roll forward | Strategies that will be updated and monitored over time | More operationally demanding and easier to misconfigure |
| Rolling-Window Validation | Train on a moving recent window and test on the next future segment | Markets where older behavior may no longer be relevant | Can discard useful historical context |
Most bad backtests don't fail because the code crashes. They fail because the researcher accidentally gave the strategy answers it wouldn't have in live trading.
That's why smart analysts still produce useless results.

Data snooping happens when you keep testing variants until something looks good, then act as if that result came from a clean process.
In DeFi, this often looks harmless. You rerun the same wallet-mirroring strategy with slightly different filters. Then you remove a few bad tokens. Then you tighten entry rules. Then you exclude an ugly month because “the market was weird.”
At the end, the strategy isn't validated. It has been negotiated into existence.
If you need a good framework for diagnosing technical and workflow issues in DeFi simulation, this guide on scalable backtesting for DeFi challenges and fixes is useful because it focuses on how backtests break under real on-chain conditions.
This is the most lethal error because it often hides inside feature engineering.
Examples from on-chain research include using a wallet label that was assigned later, ranking traders by a performance window that extends beyond the decision date, or computing token-level statistics with data that wasn't yet available at the time of the simulated trade.
A wallet-mirroring strategy should only know what a trader could have known at that timestamp. Not one block later.
If your backtest needs information that wasn't available in the moment, it isn't forecasting. It's replaying history with privileged access.
Even clean out-of-sample tests can still understate risk. Research on model validation shows that scoring metrics can rank models correctly while still underestimating the true error magnitude, which matters in crypto because regime changes can make historical out-of-sample scores less informative about future risk, as discussed in this paper on aggregate out-of-sample prediction and model validation.
That matters more in DeFi than many analysts admit. A strategy can be the least bad model in your comparison set and still be dangerous in absolute terms.
Three common regime shifts break on-chain systems fast:
Most DeFi analysts don't need more theory. They need a repeatable workflow that stops them from shipping overfit ideas. The cleanest way to do that is to treat a wallet strategy like a production model from day one.
A common practical convention is a 70/30 split, where the first 70% of a time series is used in-sample and the last 30% is held out for testing, and some practitioners use a 50/50 split for a tougher exam, according to this overview of out-of-sample testing conventions. For on-chain work, those are starting points, not sacred rules. The key is that the test block stays untouched until the strategy logic is frozen.
“Mirror smart money” is not a strategy. It's a slogan.
You need explicit rules such as:
One tool can help. Wallet Finder.ai's backtesting framework supports exporting and structuring on-chain trade histories so analysts can define rule-based tests instead of eyeballing wallet behavior.
Don't split randomly. Use earlier trades for research and later trades for testing.
For a wallet-mirroring setup, build your inclusion rules on the in-sample segment only. That includes wallet selection, token filters, and execution assumptions. Once those are set, freeze them.
Then run the unseen period without edits.
A simple pseudocode outline looks like this:
| Phase | What you do |
|---|---|
| Initial train | Build wallet filters and trade rules on the earliest segment |
| First test | Apply the frozen rules to the next unseen segment |
| Roll forward | Move the cutoff ahead and rebuild only from information available up to that point |
| Repeat | Collect all out-of-sample segments into one combined evaluation set |
A simple implementation mindset:
Here's a visual walkthrough that shows the idea in motion:
Save every assumption. If you changed the definition of a “copyable wallet,” record when and why. If you altered execution timing, document that too.
Without an audit trail, you can't tell whether the final result came from a strong edge or from a series of small, convenient edits.
Research discipline: The moment you inspect test results and then alter rules, create a new experiment. Don't pretend the old holdout is still clean.
A strategy that made money in an out-of-sample window still might be bad. Profit alone doesn't tell you whether the return came from repeatable behavior or from one lucky burst.
What matters is the shape of the returns and the risk taken to produce them.
Start with a small set and interpret them together:
If you want a practical refresher on interpreting risk-adjusted performance, this Sharpe ratio calculator guide is a useful companion when reviewing unseen-period results.
Don't hunt for one magic number. Look for alignment.
A credible strategy usually has these traits:
A suspicious strategy often has one of these patterns:
Good out-of-sample performance should make you calmer, not more excited. Excitement usually means the result is too good to trust.
Before you deploy any strategy with real capital, run this like a pre-flight check.

Most backtests fail because the researcher asks history to confirm a story. Reliable out of sample validation does the opposite. It gives history one job: disprove the idea before the market does.
If you want to test wallet-mirroring ideas with cleaner on-chain trade histories, structured exports, and alert-driven research workflows, Wallet Finder.ai is one option for turning raw wallet activity into datasets you can validate before risking capital.

A premier DeFi analytics platform empowering traders to discover and analyze profitable blockchain wallets, trades and tokens.

